
测试:品质、品牌与价值的综合体现 ——2019至顶网公有云主机评测综合分析报告(下) 原创
从上篇测试文章中我们可以了解,公有云主机的网络应用性能,与CPU的处理能力息息相关,虽然在正常应用流量测试中,绝大部分的公有云主机CPU使用并没有达到一个很高的数值,这是因为测试所搭建的网页比较简单,没有过多互动性内容而导致的。公有云主机的CPU处理能力到底如何?为什么至顶网云能力评估小组一直提倡采用双核云主机?网络、计算、存储中云主机的系统盘存储能力又是如何?这些问题我们会在这部分文章中继续为大家进行解读。
1+1<2?公有云主机计算性能结果分析
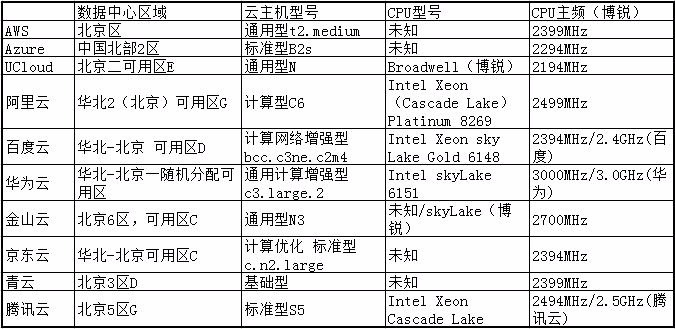
1+1=2这是一道一年级的小学生也能解答出来的算数题,可是一个虚拟的vCPU再加上一个虚拟的vCPU呢?去年就有一个公有云厂商给我们提供了一个1+1<2的测试结果。那么今年公有云厂商的云主机又会有什么样的表现呢?为此,在本测试试中,我们采用和去年相同的测试工具,对和去年相同的十个公有云厂商的公有云主机进行了测试。在本次测试中,尽量选择公有云厂商比较新的数据中心,和比较新型号的CPU进行测试,现把所选十个公有云厂商测试数据中心及CPU型号整理如下:
需要从什么角度出发展示产品?
先说一下选择公有云主机型号时所发现的问题。现在发现,有很多公有云厂商在展示自身公有云产品的时候,出于产品展示的目的,将所有的公有云主机简单粗暴的罗列出来,而不是站在用户使用的角度来对产品进行展示。对于公有云厂商来说,尽可能将自身产品展示出来这没有什么问题,完全可以理解。但是作为一个用户在选择产品的时候,就完全无所适从了!

比如在上图中,同样vCPU数量、同样内存大小的云主机型号有三、四个,到底要选那个,要靠猜!此外是有关CPU的型号,我们选用的云主机中,只有阿里、百度、华为、腾讯这四个厂商将自身的公有云主机处理器型号明确的标示了出来,而对CPU主频明确标示的更只有三家。因此在被测云主机应当如何正确选择的问题上,着实难为了我们云能力评估小组的新乐同学。
有鉴于云主机型号众多的问题并不是在一、两个公有云厂商中出现,而且越是大品牌公有云厂商,这类问题就越严重。因此,不得不在此正式提出这个问题,也希望可以得到公有云厂商们的响应,转换一下对公有云产品的展示思维,从用户角度出发、从应用角度出发,让用户把更多精力可以放到实际业务上去,而不是为基础设施的选择而浪费时间。
公有云主机性能对比
既然是对公有云主机的计算性能进行测试,那难免要来跑一下分的。下面我们还是采用Geekbench 3.4.2 for Linux x86 (64-bit)对公有云主机计算能力进行测试。同时为了对更多新业务处理能力进行评估,同时采用Geekbench 4.3.3 for Linux x86 (64-bit)对公有云主机计算能力进行评测。
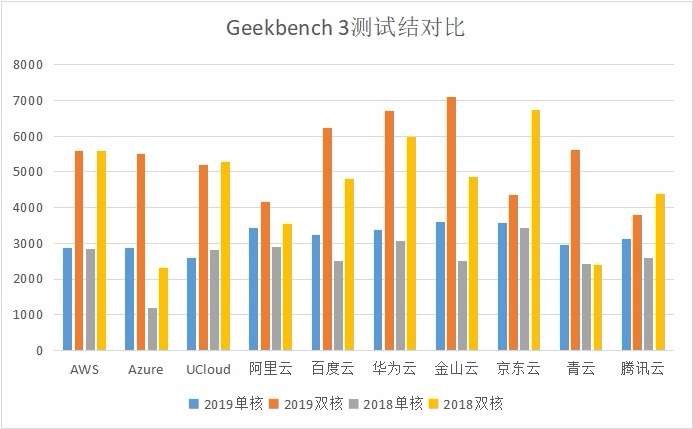
Geekbench 3测试结果对比图表
通过这个跑分成绩可以充分说明一个问题,光看跑分不靠谱!
在这个对比图表中,可以明确的看到,在今年的Geekbench 3测试成绩中,单核与双核成绩最高的是金山云的公有云主机,但是在上篇的Web应用性能测试中,唯一出现问题的也正是它。
不过对这些测试结果深度挖掘一下的话,还是可以看出一些有趣的事情来的。那就是单核与双核性能提升不成比例的公有云厂商数量有所提升。
通过上面的Geekbench 3测试结果对比图表可以看出,在2018年,只有阿里云一家出现了云主机单核计算性能与双核计算性能不是接近成比例提升的情况。可是在今年的测试中,不但阿里云的情况依旧,腾讯云和京东云也出现了和阿里云相拟的云主机单核计算性能与双核计算性能不接近成比例提升现象。计算性能关系到处理效率,一家出现这种情况,可能是技术上的问题,可是多家跟随着出现同样情况,这里面就另有内情了。
和阿里云的技术进行深入沟通之后,才了解了其中的内情。用过虚拟机的小伙伴都清楚,在一台物理主机上,可以虚拟出很多台虚拟机出来,可以多出这些虚拟机的计算能力怎么解决呢?就只能轮流来用物理的CPU了,一个虚拟机在使用的时候,其它没有分配到物理CPU的虚拟机只能在一边等着。如此一来,CPU的使用效率是提升了,但是虚拟机的业务处理能力实际上会下降的非常明显。这样的虚拟机,简单跑跑功能体验是没有问题的,但真正用在企业业务系统中,往往会出现问题,这也就是常常有人吐槽的CPU超买。实际上为了业务系统的稳定,现在超买的公有云厂商已经不多了,找个软件跑下分,一对比就可以看出来。于是通常将虚拟CPU和物理CPU做绑定。而问题就出现在这个“绑定”的方法上面。
Intel也在为提升CPU的使用效率想办法,并且推出了一个超线程技术,一个物理CPU可以支持两个线程,简单点说就是一个CPU内核可以当两个CPU来使,同时能干两件事情。同时可以做更多的事情这是一件好事,但有一个前提条件,两个线程请求的资源不能重复,如果都请求使用一些相同的计算资源或寄存器的话,也得按照先来后到的顺序排队等着。最后满打满算,超线程可以把一个CPU内核的计算性能提升出30%左右。也就是说超线程技术的1+1是小于2的。
这个超线程和公有云主机有关系吗?当然有关系!在公有云上自然要发挥CPU的最大计算效能,一个虚机如果绑定一个物理CPU内核的话,计算资源难免会出现浪费的情况,因此在现在的公有云上,一个vCPU实际上绑定的只是一个物理CPU内核两个线程中的一个。
这个时候,如果要使用一个双核公有云主机,就会出现两种情况:
1、两个线程绑定在同一个物理CPU内核之上。
2、两个线程分别分配到两个不同的物理CPU内核上,各占其中的一个线程。
在CPU计算性能测试时,这两种情况就会出现两种测试结果:
1、当两个线程绑定在同一个物理CPU内核上的时候,受到CPU内核共用计算资源的影响,公有云主机的双核计算性能就只能做到有限的提升,肯定无法实现计算能力成倍的增长。
2、当两个线程分别分配到两个不同的物理CPU内核上,各占其中的一个线程时,由于没有共用计算资源的影响,公有云主机的双核计算性能就可以做到接近成倍的计算性能提升。
从计算性能的角度来讲,当然是第二种分配方式更加理想,可以让用户得到更多的计算资源。但是从稳定性的角度来看,结果就刚好相反了。如果数据中心用户业务较少,计算资源非常充裕的话,公有云主机的计算性能确实可以得到成倍增长,但是数据中心的用户业务一但提升,公有云主机的每个vCPU线程都在面临其它公有云主机计算资源争抢的时候,就会陷入计算资源用无可用的尴尬境地了。
还是以本次性能测试中分数最高的金山云为例,在正常应用流量测试中,其CPU使用率最高就达到了99.02%,其中User的使用率仅为8.98%,有82.03%的IOWait。
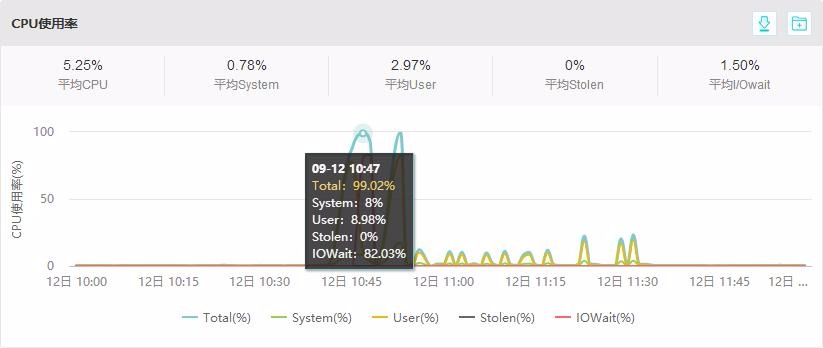
目前怀疑这高达82.03%的IOWait,很有可能就是因为计算资源被其他用户挤占所导致的。其它计算性能成倍增长的公有云主机虽然还没有出现这种情况,但是否能保证当数据中心计算资源充分利用时,不会有这种情况发生,还有待去进行更深度的技术分析。
这也许正是在公有云时代,祼金属服务器依然可以大行其道的原因吧。然而,对于那些买不起裸金属服务器的用户而言,将双核公有云主机的两个线程绑定在同一个物理CPU内核之上,就完全可以理解了,不管数据中心里有多少用户,我自家使用的计算资源始终是有保障的,人再多也抢不走!
因为没有得到其他两个公有云厂商的正式回复,因此只能是猜测,这也许是今年继阿里云公有云主机之后,京东云、腾讯云的公有云主机双核计算能力也开始变成不成比例增长的真实原因。也只有真正的有那么多用户去使用,才可以发现这种在实际应用中才能产生的问题。虽然希望今后这种不成比例增长的现象可以更多的出现,不过还是要向公有云厂商建议一下,在选择公有云主机的时候,最好可以事先将云主机计算能力分配方式说明一下,让用户可以更加明确的去进行选择。
既要有读 还得有写 公有云主机系统盘存储性能分析
在购买公有云主机的时候,往往会附带着提供一个10G到20G的系统盘存储空间,让用户进行操作系统和应用的安装,由于系统在公有云主机启动时会在内存中进行加载,而应用数据又通常会统一存储到更好性能的存储盘中去,因此系统盘的存储性能也往往会另人忽视。而对于至顶网云能力评估小组的某些同志而言,蚊子再小它也是肉,有免费的东西不用那可实在是吃亏吃大了。所以接下来我们也对公有云主机的系统盘存储性能进行了测试。
读写性能测试
在此项测试中,我们采用的是Linux下的fio测试工具,分别对公有云主机的4KB随机读、写的IOPS性能和10MB顺序读、写的带宽性能进行了测试,测试结果如下:
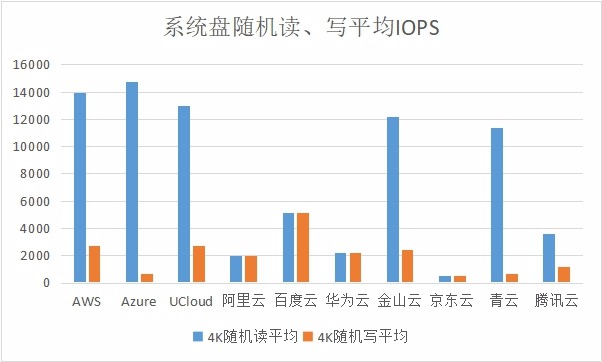
在当前的分区格式下,基本上一个簇的大小就是4K字节,也就是说你哪怕存储1个字节的文件也要占用一个4K的存储空间。所以用4K文件块大小来进行存储性能测试,可以比较准确的对存储IO性能进行测试。但是从当前的测试结果来看,在很多公有云主机的系统盘随机读与写的IOPS性能差距极大。很多公有云主机均出现非常高比例的读强写弱情况。
较高的IO读取性能固然可以为云主机提供很好的写入能力,但是过高的IO性能不加以控制的话,也是一种计算资源的浪费。在这方面阿里云、百度云、华为云和京东云的读写性能分配比较平均。但京东云存储的IOPS有控制的过低的嫌疑。而这方面百度云对存储的控制,相对来说更加适于用户的应用。
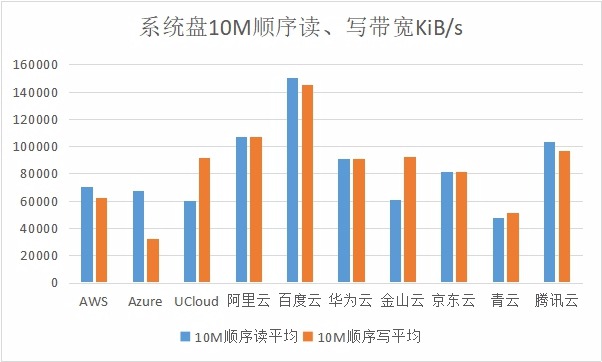
在存储性能测试中,不但要有适当的IO处理能力,还要具体合适的传输带宽。因此在本次测试中,至顶网云能力评估小组采用10MB大小文件块,对系统盘读写带宽也同样进行了测试。
在读写带宽的性能测试中,可以看出大部分国内公有云厂商在系统盘数据传输带宽方面均表现的不错。需要补充说明一下的是,本来计划在测试中采用1MB文件块大小对读写带宽进行测试,但因为有些公有云主机写IOPS性能过低,采用1MB文件块大小测试时无法准确获得其准确带宽性能,因此才放宽了标准,采用10MB文件块大小进行测试。可即便如此,在Azure、华为云、金山云、青云和腾讯云写带宽测试中,连续记录的传输带宽都有比较明显的传输波动情况出现。如此宽松条件下,写带宽传输依然存在比较明显波动,这个情况也希望可以得到相关公有云厂商的重视。
重启时间
系统盘的首要任务是满足系统和应用的加载,因此至顶网云能力评估小组也对公有云主机的重新启动时间进行了测试。

在重启时间测试中,采用对公有云主机外网IP长ping,并在命令行输入reboot的方式,通过统计丢失ping包个数,了解公有云主机的重新启动时间。
从系统盘重新启动时间对比图表可以看出,虽然AWS和Azure提供了很高的IO读取性能,但是并没有为其系统盘重启带来过多的优势。相反是读写带宽都不占优势的青云,在系统重新启动时,以2秒钟的出色表示获得了头筹。这可能是和青云公有云主机在启动时,是直接加载内存和存储的镜像文件而不是和普通计算机是通过系统盘进行文件读取有关。
以上测试成绩也可以为我们提个醒,“免费”的便宜可能并不好占,为了核心业务的稳定着想,还是将关键数据放到厂商专门提供的云存储上面会比较好。
可扩展能力明显好于去年
在去年至顶网征求用户对公有云使用意见时,有很多用户对公有云的可扩展能力表示出了不满。今年也特意对这十个公有云厂商的公有云主机可扩展功能进行了测试。

测试结果现实,当前这十家公有云厂商在增加公网带宽和提升云主机配置方面,都可以很方便的进行设置。在增加支主机方面绝大部分公有云厂商都已经提供了弹性伸缩功能,只需要事先做好伸缩配置,就可以很方面的进行公有云主机扩展应用。只有UCloud和青云还是在使用较传统的负载均衡方式对公有云主机进行扩展,不过青云的负载均衡设置也同样十分方便并不会对用户公有云主机扩展造成过大困扰。看来UCloud还要在云主机相关应用上再努点力了。
做数容易 做事太难 2019评测小结
如果要用一句话来做2019年公有云评测的总结的话,我想说的就是“做数容易,做事太难!”有些公有云厂商确实可以调制出比较出色的计算性能,但是在加载实际应用后,就什么问题都出现了。有些公有云厂商的性能指标都不是很突出,但业务应用跑得却十分顺畅。
当然,在这里至顶网云能力评估小组首先要检讨一下我们自身的问题,以前作者在做网络和网络安全产品测试的时候,确实习惯了使用专业的性能测试仪表,那个时候就好像手握玄铁重剑一样,可以轻松的将产品性能压到极致,好坏高下一眼就可以看出来了。可以在公有云上则完全不同,基本找不到通用的专业测试工具可用,只好找些寻常的刀剑,好在是发现了一些破绽,要不还真是不好走下台去了。但是,只有不断的去发现问题,解决问题,才能不断的进步。对产品厂商如此,对测试技术来讲也是如此!玄铁重剑不好找,寻常刀剑不好用,那我们就要想办法打造出更适用的倚天剑来,到时候再好好和产品研发的屠龙刀再比试一下。
这把倚天剑要怎么打,计划将抽时间总结一下本次测试中的经验教训,再和众多测试软件、测试工具厂商多多进行沟通。计划以功能测试为基础,结合一些关键性的应用性能指标,逐步完善出一套可实用的测试方案出来。有机会的话也会另外撰文,对这方面技术进行一下更深度的分析。
总而言之,我们坚信,正因为不存在绝对的完美,我们才会不断的去追求完美,不断的去发现问题、解决问题,才会不断的取得新进步,产品如是,测试亦如是。
有关于这十个公有云的评价,我们书葆同学提议组织互联网企业的专家用户来进行打分。对这个提供我举双手赞成。专业的事性由专业的人来做,做评测我们专业,可以把问题点找出来,但对产品做评价还是真正有使用经验的人更具有发言权。至顶网云能力评估小组要做的就是将产品最真实的一面,切切实实的展示出来,用户自然会做出最明确的选择。
未来我们还会更进一步的对区块链、5G、边缘计算、数据库、人工智能、大数据分析等技术做进一步的评估分析工作。千万不要以为这是在喊喊口号,为此我已经准备了一个商铺,准备找到业主后帮他做数字化转型,可没想到近一年了也没租出去……这也可能就是传统零售遇冷,无力进行数字化转型的一个缩影吧。但我们还是坚信传统企业数字化转型的未来是光明的。区块链的溯源机制,为生产企业产品品质提供了保障,未来假货泛滥的情况会得到遏制。5G的低延迟、大带宽、支持海量用户应用,将为产品生产、加工、销售全流程质量监督打下基础。边缘计算行为分析可以为所有环节出现异常及时告警。至于产、销、存的大数据分析又可以为产品生产规划做出精准的分析。传统企业向数字化转型的大路已经铺到我们眼前,所缺少的就是一个转型成功的最佳实践。而我们至顶网云能力评估小组不但会尽好媒体监督职责,还会通过我们最丰厚的专业技术积累为用户做好参谋,让用户用更少的投资,让企业走更少的弯路,顺利的在数字化转型大道上大步向前。
好文章,需要你的鼓励


星际之门AI数据中心建设雄心遭遇现实挑战
2025年1月,OpenAI、软银、甲骨文和MGX联合宣布"星际之门"计划,承诺投资5000亿美元,部署高达10GW算力基础设施。如今,该项目已从白宫发布会上的宏大承诺,演变为一场前所未有规模的基础设施建设实验。项目已扩展至德克萨斯、威斯康星、俄亥俄等多地,并延伸至阿布扎比和挪威。然而,融资争议、合作伙伴摩擦、能源压力及政策监管收紧,正考验着这一"AI工业园"模式能否真正落地。

阿里巴巴让AI图像生成模型“自我进化“:Qwen-Image-2.0-RL是如何让机器学会审美的?
阿里Qwen团队通过引入强化学习和在线策略蒸馏,将Qwen-Image-2.0升级为Qwen-Image-2.0-RL,让图像生成模型真正学会人类审美,文生图Elo评分提升78分,图像编辑提升93分。

OKX推出AI智能体招聘与支付市场平台
加密货币交易所OKX正式推出AI智能体交易市场OKX AI,允许AI代理相互雇佣、自主结算,并建立基于区块链的可携带信誉档案。该平台经过50家早期服务商封测后向开发者开放,依托稳定币和链上支付基础设施,支持全天候微支付。OKX创始人徐明星表示,传统金融基础设施为人类而建,智能体经济需要为自主软件专门设计的基础设施。

港科大联手快手,让AI画图“减减肥“:一个让图像生成更真实的小技巧
港科大与快手联合提出NormGuard,针对流匹配模型强化学习训练中速度范数膨胀问题,通过训练时单向惩罚约束,在保留奖励的同时改善图像真实感。
2019
11/26
11:46
分享
点赞

星际之门AI数据中心建设雄心遭遇现实挑战
OKX推出AI智能体招聘与支付市场平台
AI编程Token成本将与开发者薪资持平,企业如何应对?
机器学习项目全生命周期管理的成功实践
SVT Robotics的Softbot平台交易量突破40亿笔
Agibot第15000台人形机器人下线,具身AI量产加速
杜尔为大众汽车建设跨工厂集成CO?高效涂装车间
AI对就业的影响:大规模裁员背后的真相与数据
AI重复申请问题推动电网转向"承诺优先"规划
美国消费品安全委员会拟出台电动自行车电池安全新规
江波龙:建设完成mSSD月产能百万交付能力!mSSD高速存储介质赋能端侧AI规模应用
从IO500双榜第一,看国产存储的系统级突破
Gartner:到2025年,全球公有云终端用户支出将达到7230亿美元
Gartner:2023年全球IaaS公有云服务收入增长16.2%
Gartner预测2024年全球公有云终端用户支出将超过6750亿美元
四大顶流AI绘图模型真实评测 - Midjourney、Adobe、SD、DALLE
Gartner:可持续发展和数字主权将作为选择公有云生成式AI服务的首要标准
数据中心无法实现自动化的5件事
为33家企业测过大模型的“方升”,是一个怎样的评测体系?
公有云关系型数据库持续高增长,阿里云占比39%蝉联榜首
Gartner预测:2024年全球公有云终端用户支出将达6790亿美元
Gartner预测2024年全球公有云终端用户支出将达到6790亿美元
