
Intel Skylake-SP处理器评测(一) 原创
Intel将上一代Broadwell-EP处理器的改进分为了三个方面:Orchestration(编排)、Security(安全)和Performance(性能),其中,Orchestration(编排)是一个在Broadwell-EP上提出的新概念,核心就是Intel Resource Director Technology(RDT,资源管理技术),笔者认为,这是Broadwell-EP上带来的最重要也是最显著的一个变化。到了Skylake-SP,Xeon家族的信念具有了一个飞跃,新的重点囊括为三个:Performance(性能)、Security(安全)和Agility(敏捷):
如下图所示,可以看出:

Intel Xeon Scalable Processor: Performance, Security and Agility
敏捷取代了编排,可以很容易认识到的是,敏捷包含了编排,可以说,Xeon Scalable处理器具有着更多的野心,也搭载了更多的特性,从而,它也需要着更多的微架构/架构改变:

Intel Skylake-SP——初代Xeon Scalable处理器家族的特性改进一览
我等不及要对这些提升一一讨论了:
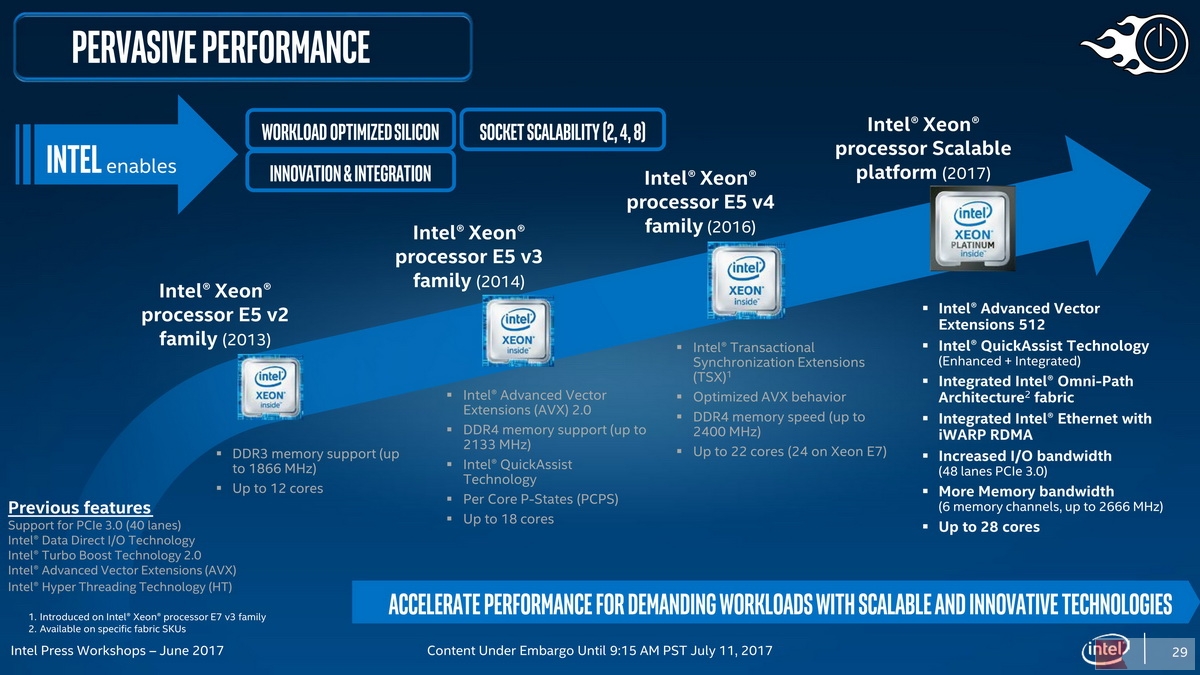
Intel Skylake-SP处理器:历代性能提升
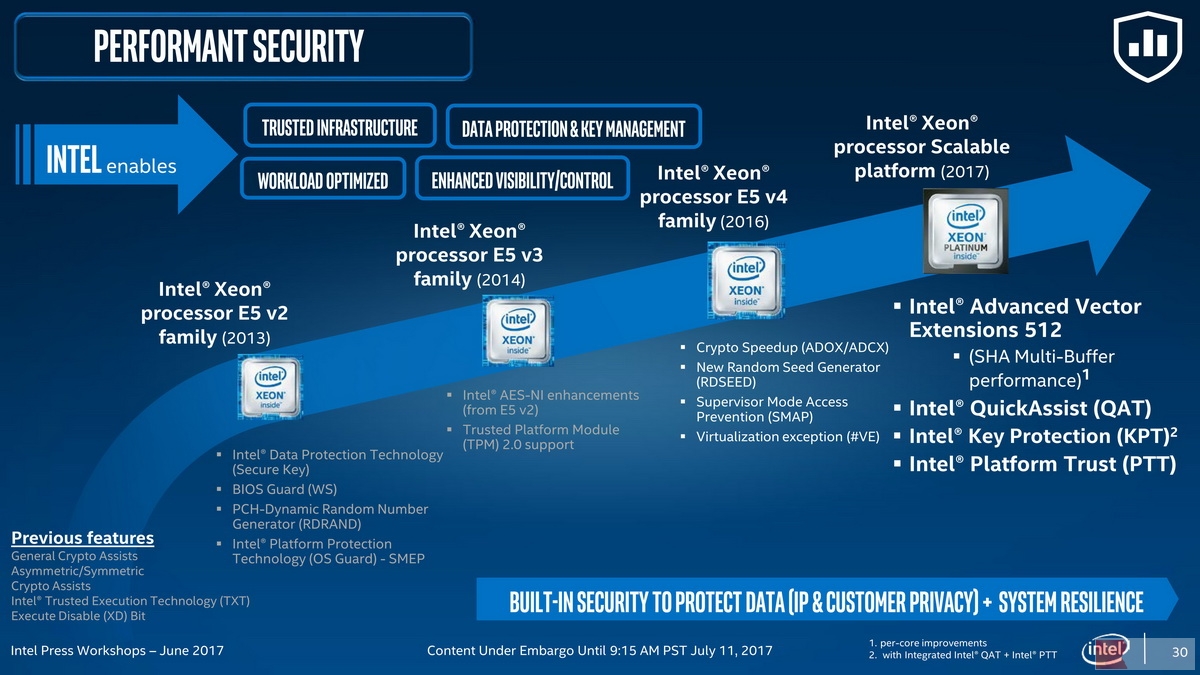
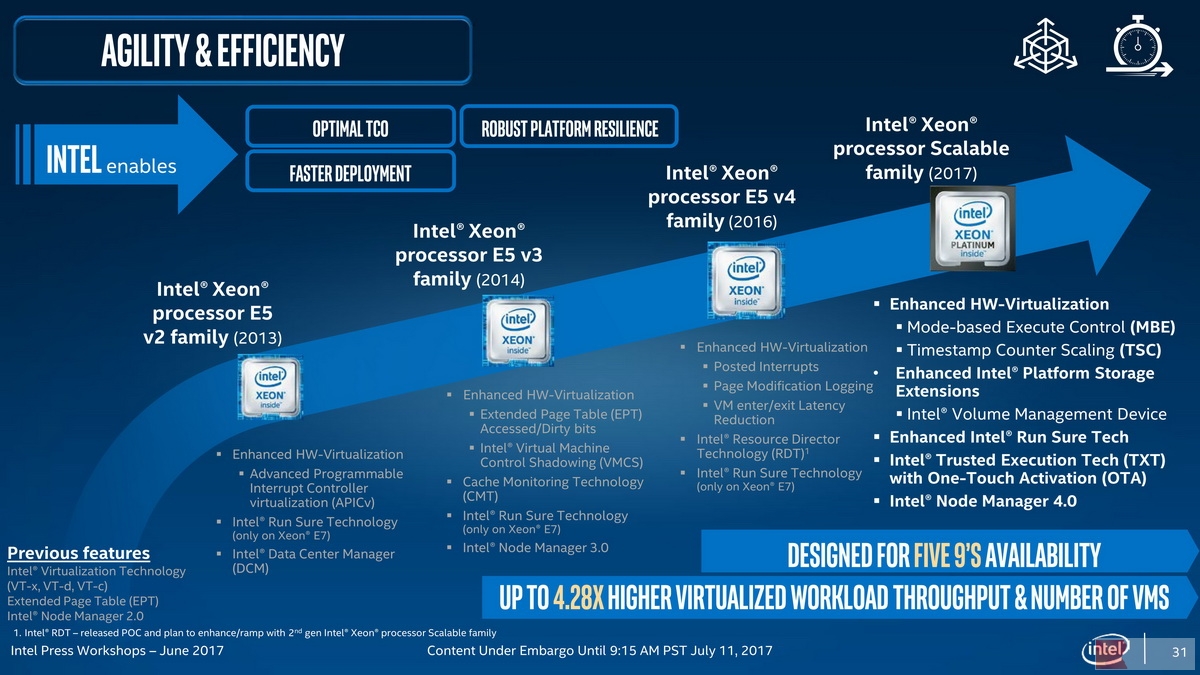
Intel Skylake-SP——初代Xeon Scalable处理器特性一览
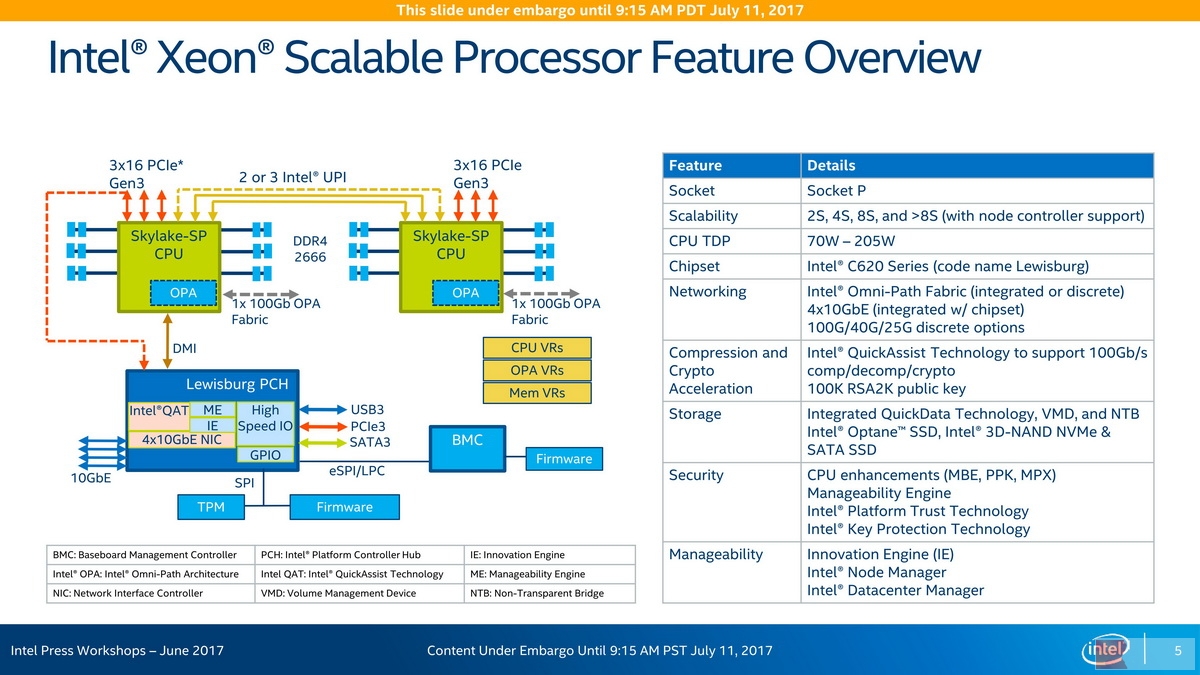
Intel Skylake-SP搭配的Lewisburg PCH芯片组的进化也颇值得一提,但这部分内容我们决定放在以后的文章当中。
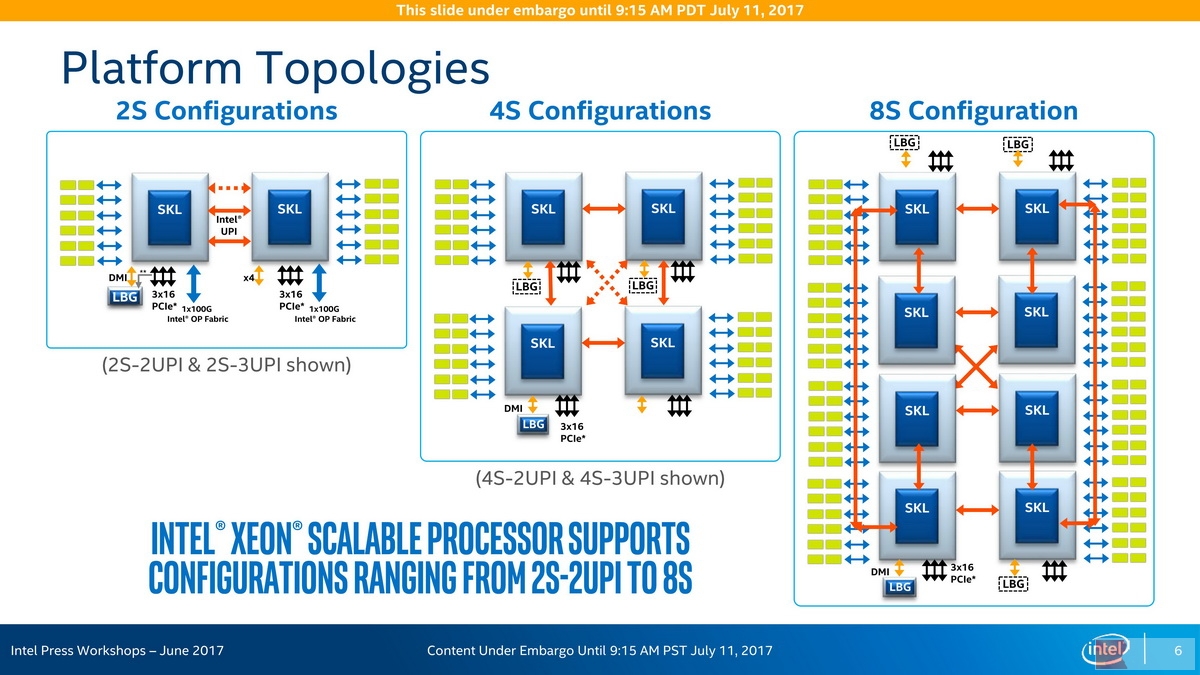
由于每处理器最多具有3个UPI外联总线,因此Glueless模式仍然支持到8路系统为止,但现在2个UPI的型号也可以支持环形的四路配置;理论上,环形配置可以支持无限多的处理器(考虑一个无限大的处理器首尾连接的圆环),只是延迟也会线性地增加

Intel Xeon Scalable Processor: Re-architected from the Ground Up
初代Xeon Scalable处理器搭配了支持AVX-512指令集的微架构,可以一次性处理512位数据,并且可以每处理器达到28个核心,支持6个内存通道,更多的PCIe 3.0信道,更多的性能、安全特性以及更新更强的PCH。Intel号称其为Re-architected from the Ground Up,从头重新架构,且让我们从头开始,从Skylake的微架构开始一一介绍。
来源:至顶网CBSi企业方案解决中心频道
好文章,需要你的鼓励


埃森哲投资Profitmind,押注AI智能体变革零售业
埃森哲投资AI零售平台Profitmind,该平台通过智能代理自动化定价决策、库存管理和规划。研究显示AI驱动了2025年假日购物季20%的消费,约2620亿美元。部署AI代理的企业假日销售同比增长6.2%,而未部署的仅增长3.9%。Profitmind实时监控竞争对手价格和营销策略,并可创建生成式引擎优化产品文案。

上海AI实验室让机器人“睁眼看世界“:用视觉身份提示技术让机械臂学会多角度观察
上海AI实验室联合团队开发RoboVIP系统,通过视觉身份提示技术解决机器人训练数据稀缺问题。该系统能生成多视角、时间连贯的机器人操作视频,利用夹爪状态信号精确识别交互物体,构建百万级视觉身份数据库。实验显示,RoboVIP显著提升机器人在复杂环境中的操作成功率,为机器人智能化发展提供重要技术突破。

CES 2026:日立与英伟达、谷歌云、Nozomi Networks达成合作协议
日立公司在CES 2026技术展上宣布了重新定义人工智能未来的"里程碑式"战略,将AI直接应用于关键物理基础设施。该公司与英伟达、谷歌云建立重要合作伙伴关系,并扩展其数字资产管理平台HMAX,旨在将AI引入社会基础设施,变革能源、交通和工业基础设施领域。日立强调其独特地位,能够将AI集成到直接影响社会的系统中,解决可持续发展、安全和效率方面的紧迫挑战。

英伟达团队突破AI训练瓶颈:让机器人同时学会多种技能不再“顾此失彼“
英伟达研究团队提出GDPO方法,解决AI多目标训练中的"奖励信号坍缩"问题。该方法通过分别评估各技能再综合考量,避免了传统GRPO方法简单相加导致的信息丢失。在工具调用、数学推理、代码编程三大场景测试中,GDPO均显著优于传统方法,准确率提升最高达6.3%,且训练过程更稳定。该技术已开源并支持主流AI框架。


{kind=link}
{kind=link}
{kind=link}
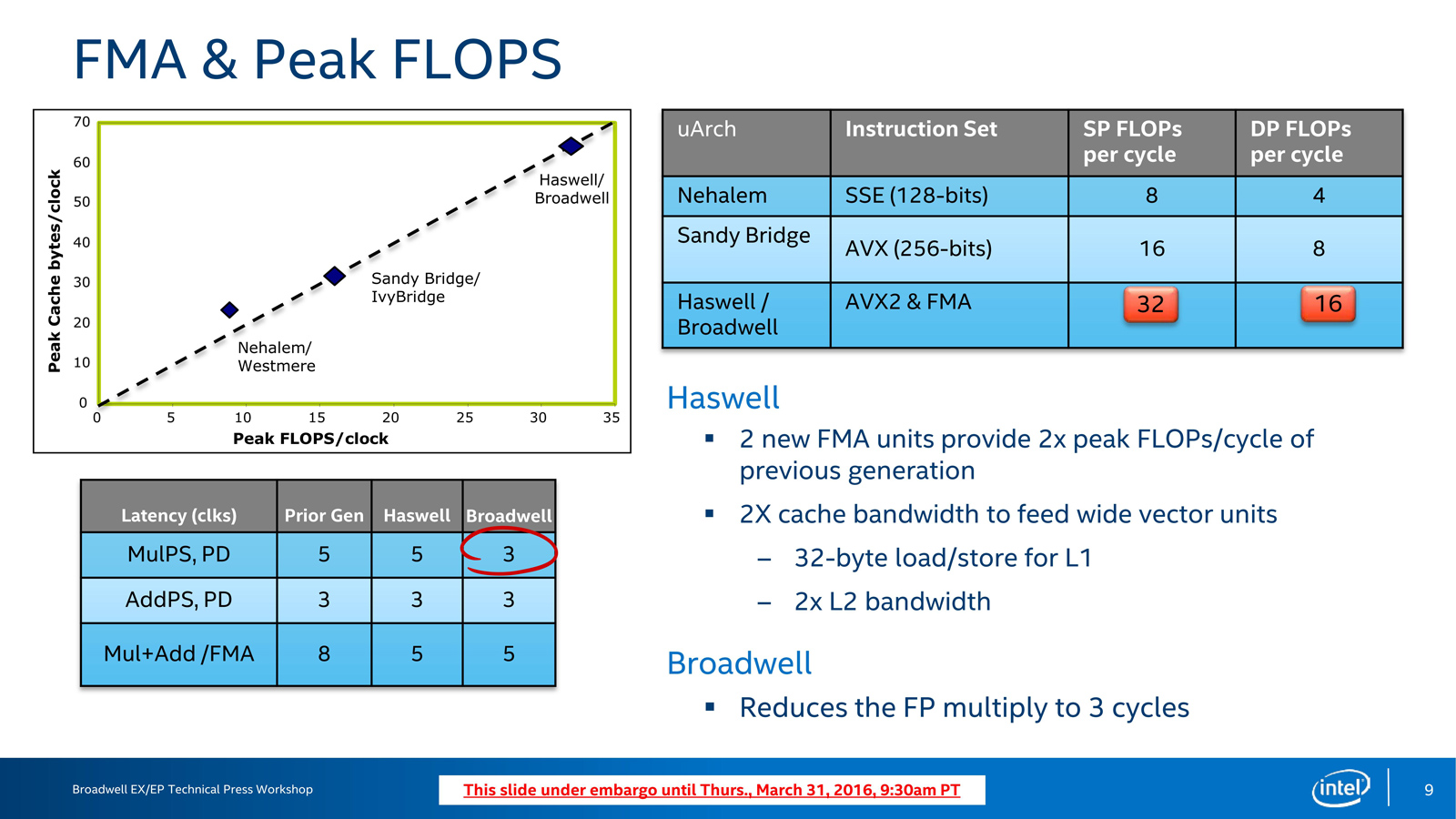{kind=link}