
Intel Skylake-SP处理器评测(一) 原创
一般而言,尽管采用了共享微架构的方案,但由于企业级别应用所需要的更多的RAS,以及更多的面向企业级应用的特性,服务器处理器版本的发布一直要晚于客户端处理器版本,Skylake的桌面版就早在2015年发布,比服务器版早了两年。共享微架构就意味着,桌面版本和企业版本的微架构是一致的,但到了Skylake-SP,情况有了些变化,且让我们从Haswell/Broadwell微架构图开始:

Haswell Core at a Glance,Haswell以及其下一代Broadwell的微架构变化不算太大

Haswell与其上一代Ivy Bridge相比最大的变化就是执行单元端口从6个提升到了8个

可见,Broadwell的微架构算是小修小补,而Skylake和Haswell一样都是架构明显变化,下图是官方文档《Intel 64 and IA-32 Architectures Optimization Reference Manual》中的Skylake微架构截图:
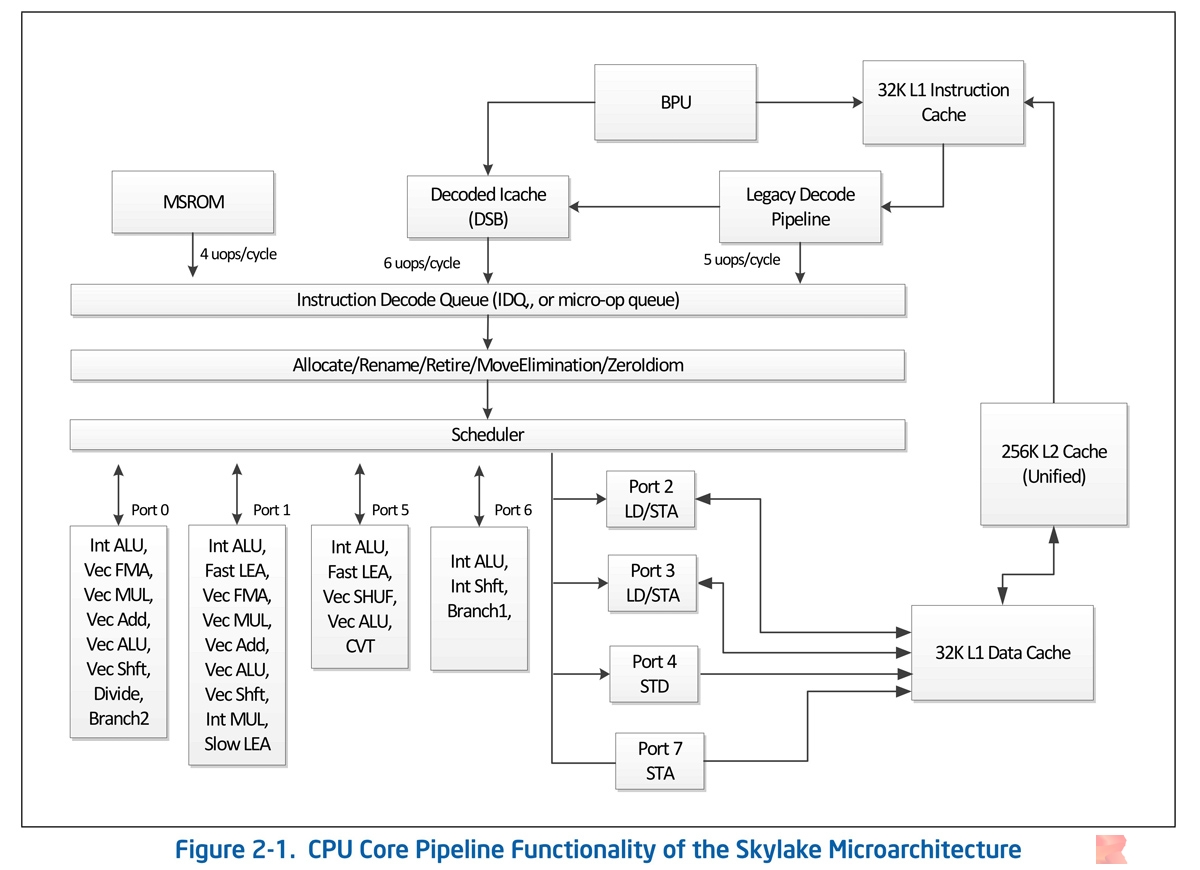
Intel Skylake Microarchitecture,这个Skylake是桌面端的
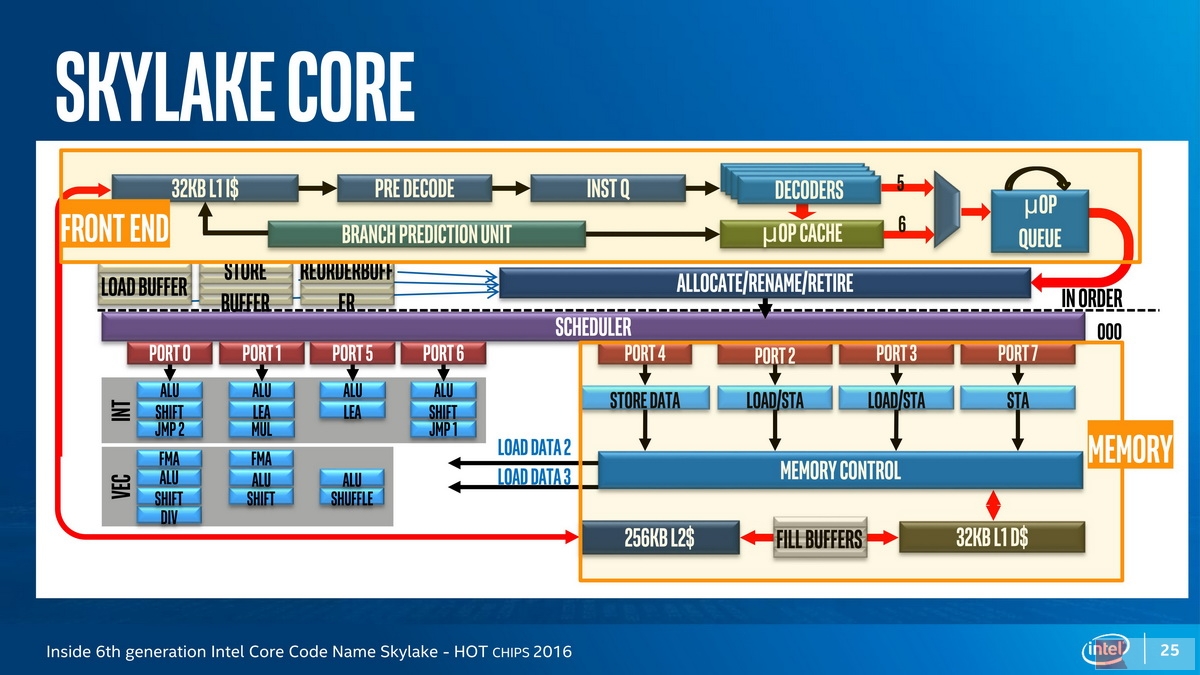
Hot Chips 2016上的报告《Inside 6th generation Intel Core Code Name Skylake》也给出了类似的微架构
可见看到,即使是桌面版的Skylake,也具有着非常明显的变化,对处理器关注不多的同学可能难以留意到Skylake在处理器微架构前端的变化:
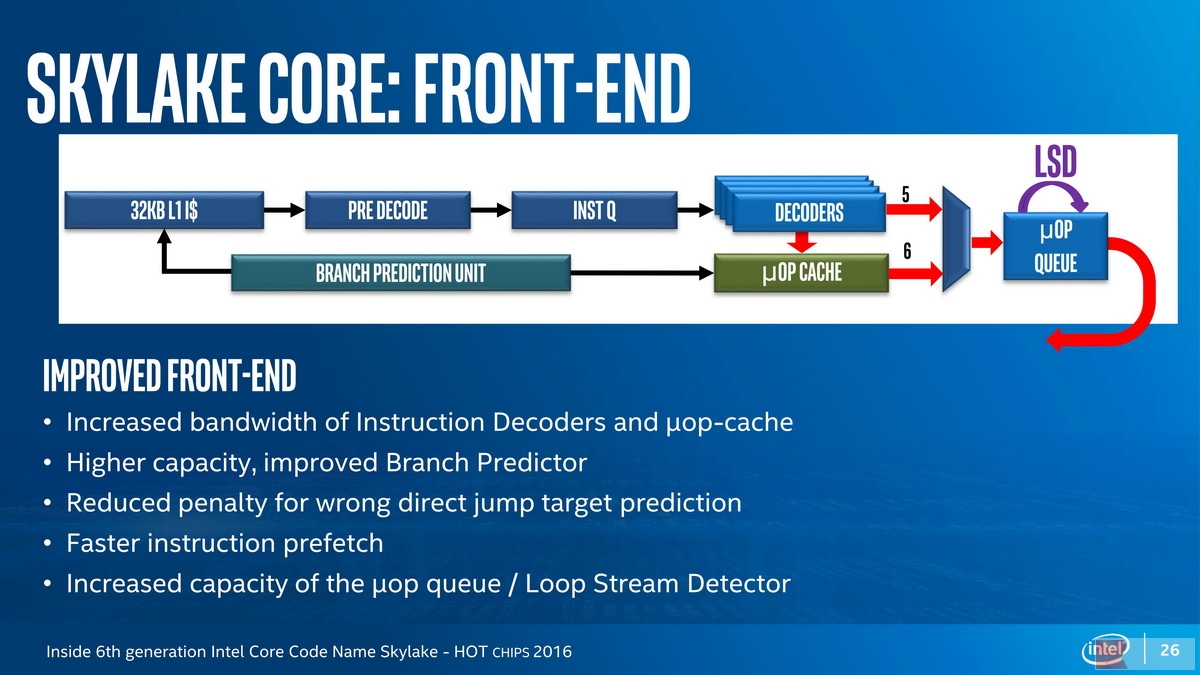
Skylake Core Front-End: The wider Issuses Width
请记住,在Skylake之前,Intel的处理器除了安腾,都是4 Issue(称为4发射)的,一直以来,Intel都将其称为“Wide Dynamic Execution(宽动态执行)” ,指的就是解码器的输出宽度,Skylake的解码器输出宽度从4提升到了5,这可以进一步Xeon处理器家族的性能。
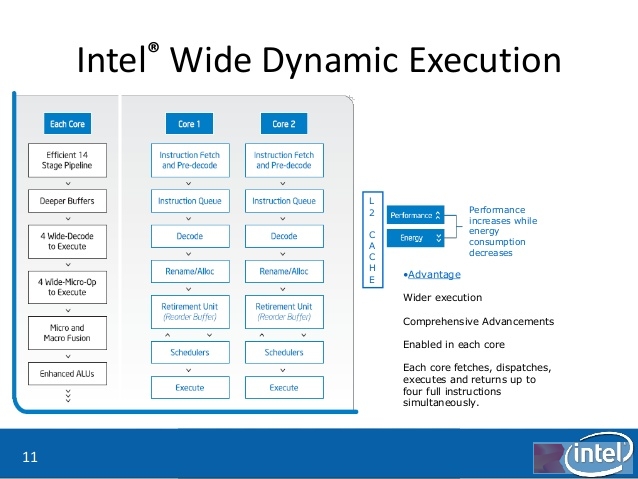
Core 2 Duo上出现的Intel Wide Dynamic Execution
需要知道的是,解码器用于将强大但是复杂、不定长的x86指令(被称为macro-op)翻译为简单、定长的uops(micro-op),从而实现了RISC-like的微架构执行,同时获得了CISC和RISC的优点——核心就在于解码器。Skylake上不仅(包括简单解码器以及microcode解码器)在内的解码器宽度得到了提升,与分支预测单元合作的uop Cache也得到了加大,分支单元有所强化。
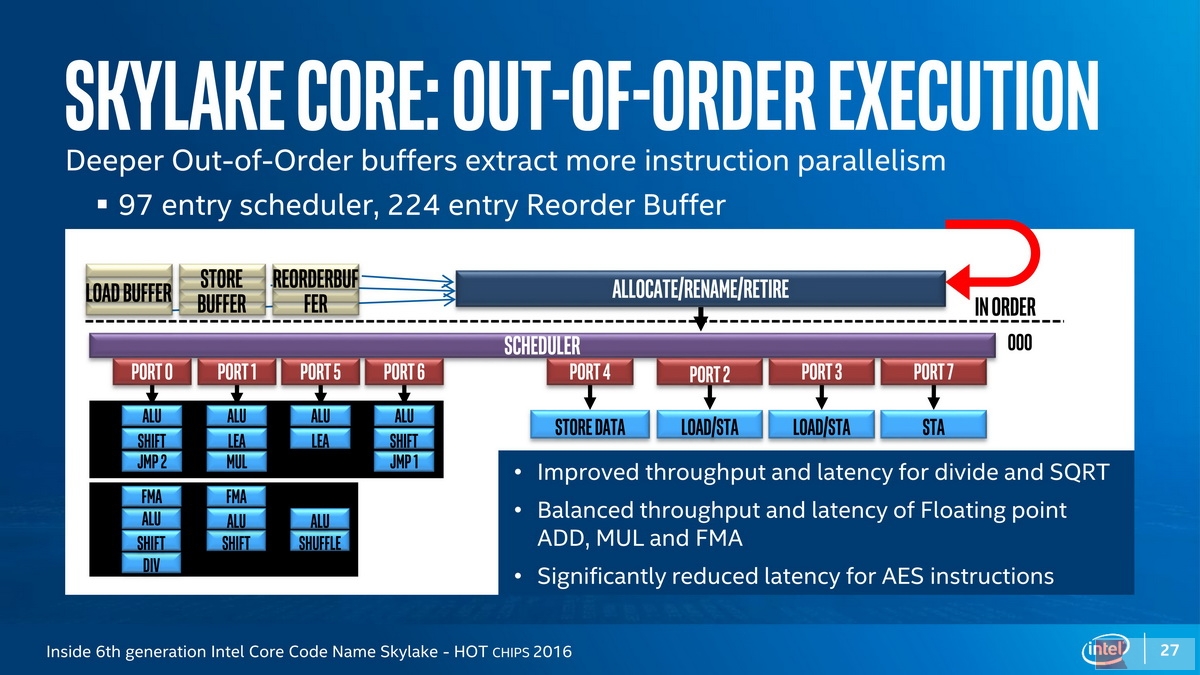
Skylake Core Back-End: Out-of-Order Execution
Front-End为IOE(In-Order Execution,顺序执行)架构,Back-End则是OOOE(Out-of-Order Execution,乱序执行)架构,在这里,会首先通过一个Rename单元将寄存器重命名,这个单元有时也与Retire回退单元结合,在Skylake上,整数寄存器增加了12个而达到180个,这与AVX-512指令集的增加有关。在共享的Skylake微架构上,除法和平方根(SQRT)运算得到了吞吐量的加强和延迟的降低(SQRT一般依赖于除法器),另外,浮点ADD、MUL和FMA的吞吐量和延迟性能也得到了增强,AES加密指令的延迟也得到了显著的降低。Skylake的Sheduler条目从60提升到97,ROB(Reorder Buffer)条目从192提升到224,Allocate Queue(与寄存器重命名一起工作)从Broadwell的56条目提升到了每线程64(合计128)条目,Intel预计Skylake-SP具有超过10%的IPC性能提升:
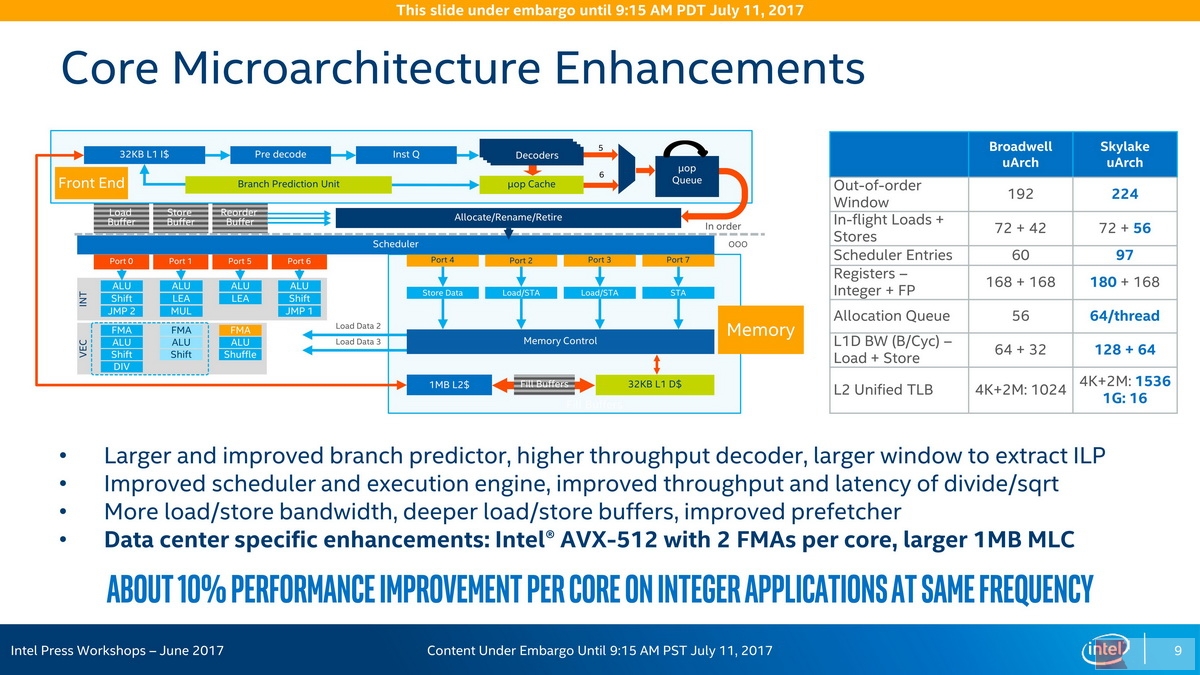
Intel Skylake-SP Core Microarchitecture Enhancements
大家都知道,Skylake-SP一个显著的变化就是引入了Xeon Phi最先装备的AVX-512指令集,它将向量运算的宽度从AVX2的256位提升到了512位,除了要求寄存器宽度同样加大一倍之外,它也需要运算单元的宽度加大一倍,在Skylake-SP上可以同时执行两个512位AVX向量运算,其中一个由原本256位宽度的Port 0和Port 1融合而成,另一个则是由Port 5端口扩展而成,这两个512位执行端口都可以支持512位FMA融乘加操作,但是,只有高端的Skylake-SP(Platinum 81xx和Gold 61xx)才具备Port 5的FMA融乘加单元。此外,桌面端(除了与Skylake-SP同源的Skylake-E之外)不支持AVX-512指令,这是因为这个功能需要额外的晶体管:

Skylake-SP Core:在标准Skylake Core微架构之外附加额外的512位端口5能力扩展与额外的768KiB L2 Cache扩展
Skylake-SP(以及Skylake-E)的AVX-512和第二个FMA,以及与普通Skylake相比多出的768KiB L2缓存,是在标准的Skylake Core之外的地方实现的,这部分区域已经属于Uncore核外区域,但被Skylake-SP拿来融入Core核内做核内用途。只有Skylake-SP有这些可能性进行这个操作,因为企业级处理器的Uncore区域向来都是采用与桌面端Uncore不同的特别设计。由于Skylake-SP的额外占用Uncore空间的设计,Skylake-SP的每核心L3 Cache容量比以往有所降低,测试表明这样的设计仍然是值得的,因为Skylake Core的内存子系统进行了相当多的优化:
2017-07-14勘误:E是以前由对应Xeon的某个型号改头换面的Core i7至尊版酷睿的代号后缀,Skylake的对应版本已经更改为X后缀——Skylake-X,对应地,Core命名的系列名变成了i9。

Skylake-SP Core:内存子系统
从参数上看,Skylake-SP的L1 D-Cache的吞吐量得到了倍增,以满足AVX-512向量指令的数据宽度倍增的情况,Skylake的Cache/TLB子系统也得到了全面的提升。关于AVX-512指令集,以及内存子系统方面的内容,我们放在了下一篇文章当中,接下来我们先看看我们先完成的SPEC CPU2006测试套件的其中一个配置的测试。
来源:至顶网CBSi企业方案解决中心频道
好文章,需要你的鼓励


埃森哲投资Profitmind,押注AI智能体变革零售业
埃森哲投资AI零售平台Profitmind,该平台通过智能代理自动化定价决策、库存管理和规划。研究显示AI驱动了2025年假日购物季20%的消费,约2620亿美元。部署AI代理的企业假日销售同比增长6.2%,而未部署的仅增长3.9%。Profitmind实时监控竞争对手价格和营销策略,并可创建生成式引擎优化产品文案。

上海AI实验室让机器人“睁眼看世界“:用视觉身份提示技术让机械臂学会多角度观察
上海AI实验室联合团队开发RoboVIP系统,通过视觉身份提示技术解决机器人训练数据稀缺问题。该系统能生成多视角、时间连贯的机器人操作视频,利用夹爪状态信号精确识别交互物体,构建百万级视觉身份数据库。实验显示,RoboVIP显著提升机器人在复杂环境中的操作成功率,为机器人智能化发展提供重要技术突破。

CES 2026:日立与英伟达、谷歌云、Nozomi Networks达成合作协议
日立公司在CES 2026技术展上宣布了重新定义人工智能未来的"里程碑式"战略,将AI直接应用于关键物理基础设施。该公司与英伟达、谷歌云建立重要合作伙伴关系,并扩展其数字资产管理平台HMAX,旨在将AI引入社会基础设施,变革能源、交通和工业基础设施领域。日立强调其独特地位,能够将AI集成到直接影响社会的系统中,解决可持续发展、安全和效率方面的紧迫挑战。

英伟达团队突破AI训练瓶颈:让机器人同时学会多种技能不再“顾此失彼“
英伟达研究团队提出GDPO方法,解决AI多目标训练中的"奖励信号坍缩"问题。该方法通过分别评估各技能再综合考量,避免了传统GRPO方法简单相加导致的信息丢失。在工具调用、数学推理、代码编程三大场景测试中,GDPO均显著优于传统方法,准确率提升最高达6.3%,且训练过程更稳定。该技术已开源并支持主流AI框架。


{kind=link}
{kind=link}
{kind=link}
{kind=link}