
Intel Skylake-SP处理器评测(一) 原创
一般而言,尽管采用了共享微架构的方案,但由于企业级别应用所需要的更多的RAS,以及更多的面向企业级应用的特性,服务器处理器版本的发布一直要晚于客户端处理器版本,Skylake的桌面版就早在2015年发布,比服务器版早了两年。共享微架构就意味着,桌面版本和企业版本的微架构是一致的,但到了Skylake-SP,情况有了些变化,且让我们从Haswell/Broadwell微架构图开始:

Haswell Core at a Glance,Haswell以及其下一代Broadwell的微架构变化不算太大

Haswell与其上一代Ivy Bridge相比最大的变化就是执行单元端口从6个提升到了8个

可见,Broadwell的微架构算是小修小补,而Skylake和Haswell一样都是架构明显变化,下图是官方文档《Intel 64 and IA-32 Architectures Optimization Reference Manual》中的Skylake微架构截图:
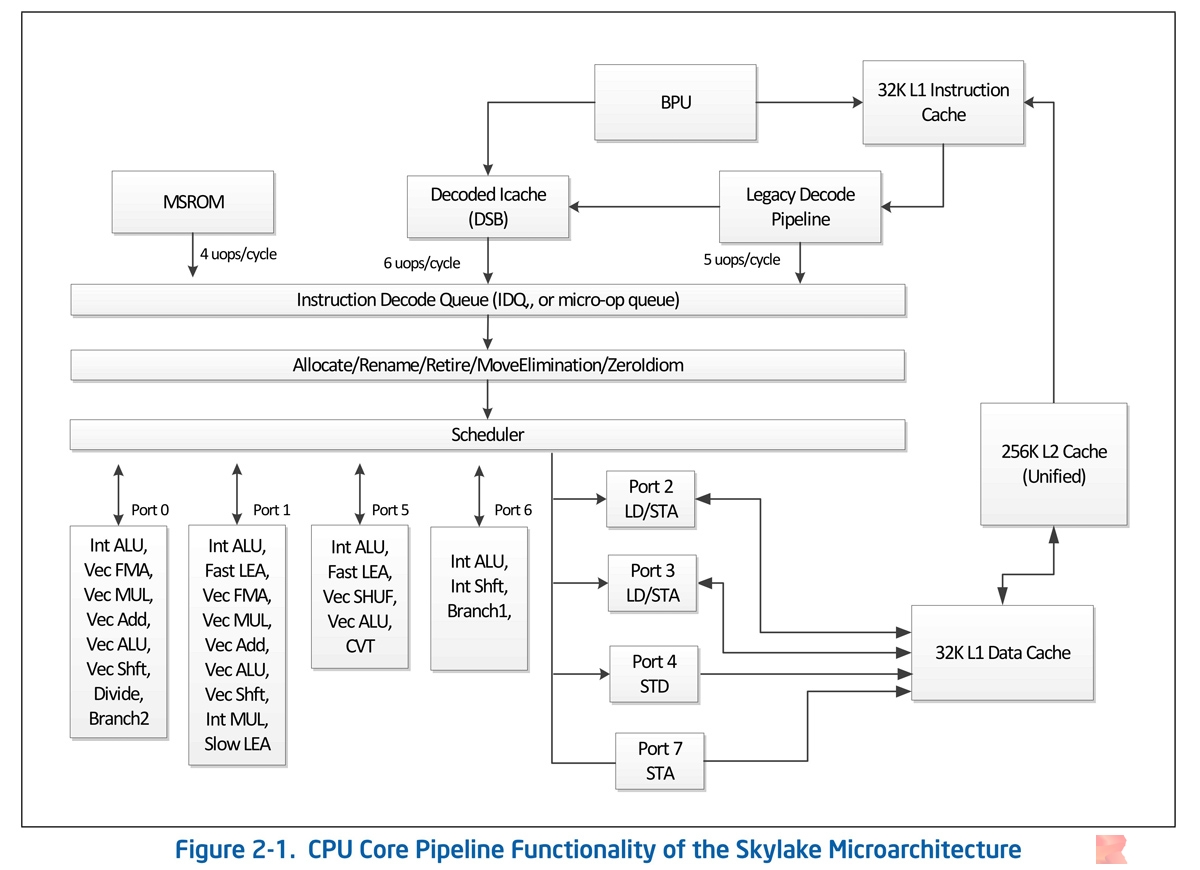
Intel Skylake Microarchitecture,这个Skylake是桌面端的
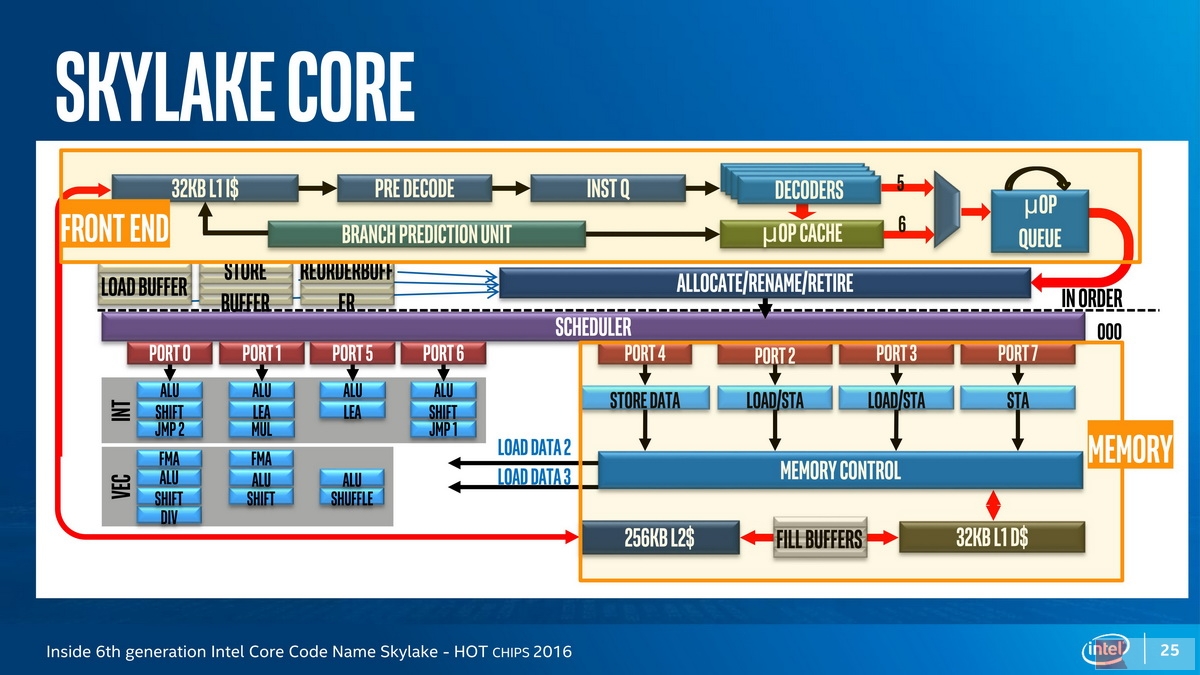
Hot Chips 2016上的报告《Inside 6th generation Intel Core Code Name Skylake》也给出了类似的微架构
可见看到,即使是桌面版的Skylake,也具有着非常明显的变化,对处理器关注不多的同学可能难以留意到Skylake在处理器微架构前端的变化:
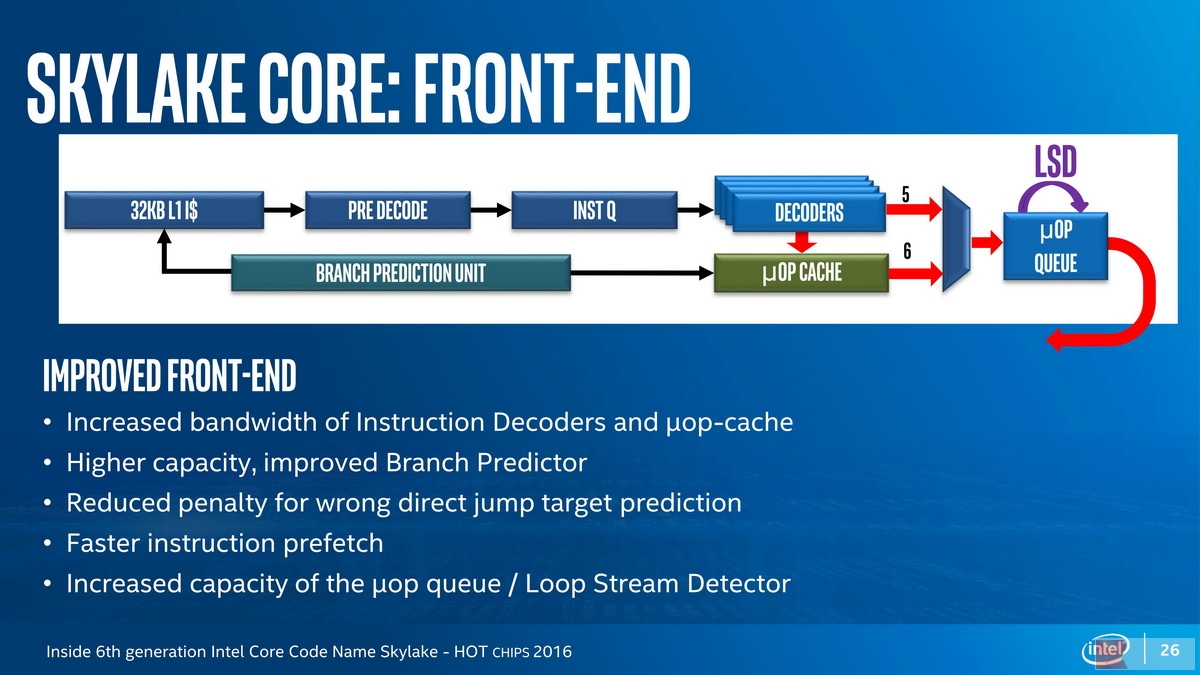
Skylake Core Front-End: The wider Issuses Width
请记住,在Skylake之前,Intel的处理器除了安腾,都是4 Issue(称为4发射)的,一直以来,Intel都将其称为“Wide Dynamic Execution(宽动态执行)” ,指的就是解码器的输出宽度,Skylake的解码器输出宽度从4提升到了5,这可以进一步Xeon处理器家族的性能。
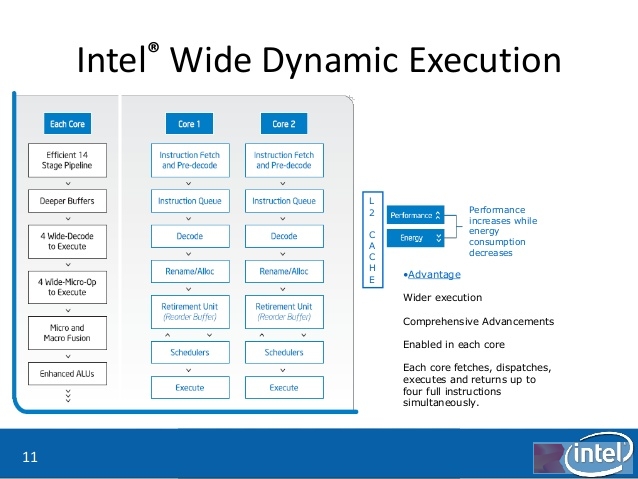
Core 2 Duo上出现的Intel Wide Dynamic Execution
需要知道的是,解码器用于将强大但是复杂、不定长的x86指令(被称为macro-op)翻译为简单、定长的uops(micro-op),从而实现了RISC-like的微架构执行,同时获得了CISC和RISC的优点——核心就在于解码器。Skylake上不仅(包括简单解码器以及microcode解码器)在内的解码器宽度得到了提升,与分支预测单元合作的uop Cache也得到了加大,分支单元有所强化。
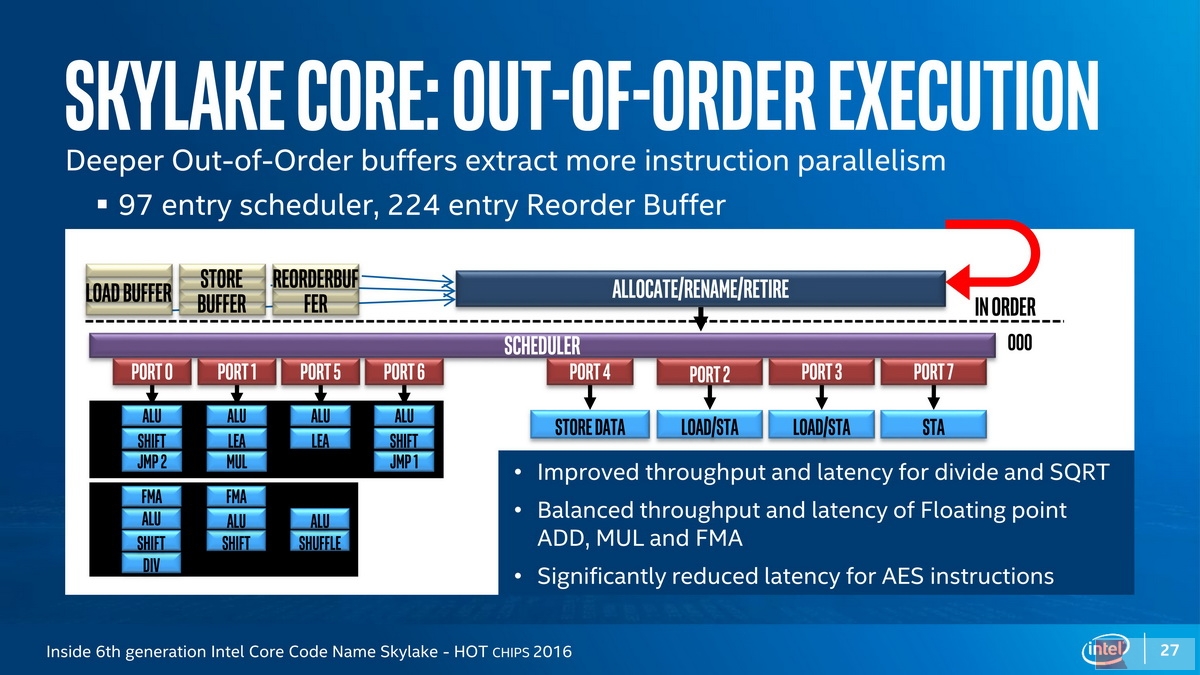
Skylake Core Back-End: Out-of-Order Execution
Front-End为IOE(In-Order Execution,顺序执行)架构,Back-End则是OOOE(Out-of-Order Execution,乱序执行)架构,在这里,会首先通过一个Rename单元将寄存器重命名,这个单元有时也与Retire回退单元结合,在Skylake上,整数寄存器增加了12个而达到180个,这与AVX-512指令集的增加有关。在共享的Skylake微架构上,除法和平方根(SQRT)运算得到了吞吐量的加强和延迟的降低(SQRT一般依赖于除法器),另外,浮点ADD、MUL和FMA的吞吐量和延迟性能也得到了增强,AES加密指令的延迟也得到了显著的降低。Skylake的Sheduler条目从60提升到97,ROB(Reorder Buffer)条目从192提升到224,Allocate Queue(与寄存器重命名一起工作)从Broadwell的56条目提升到了每线程64(合计128)条目,Intel预计Skylake-SP具有超过10%的IPC性能提升:
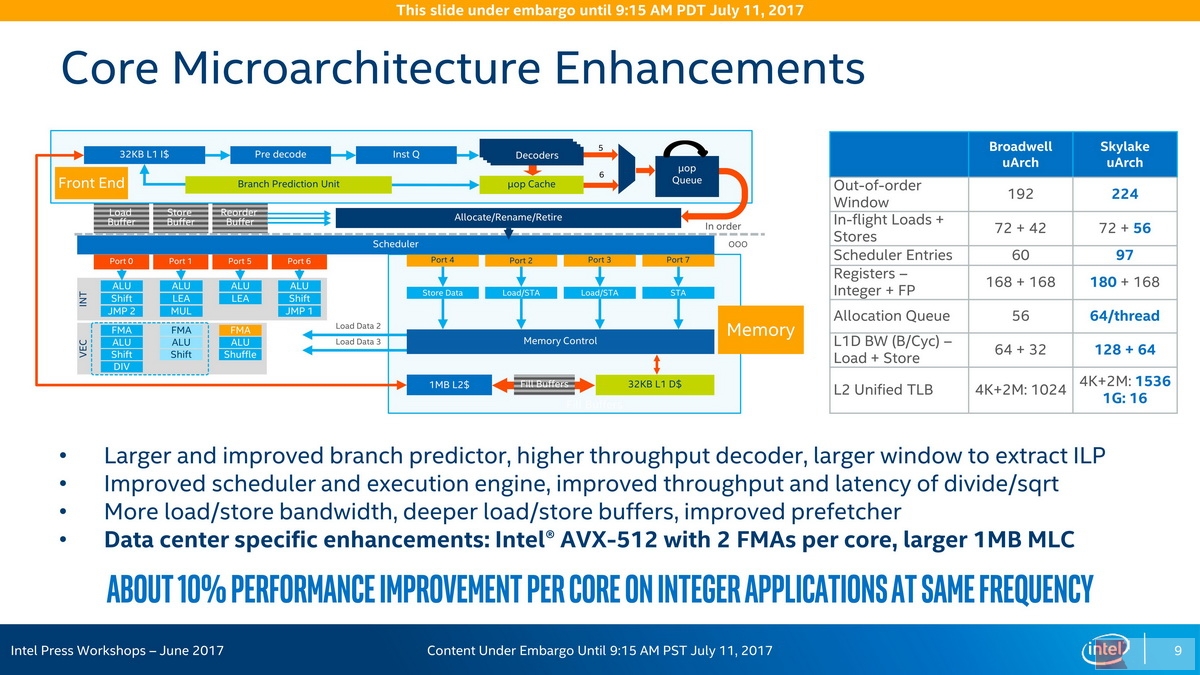
Intel Skylake-SP Core Microarchitecture Enhancements
大家都知道,Skylake-SP一个显著的变化就是引入了Xeon Phi最先装备的AVX-512指令集,它将向量运算的宽度从AVX2的256位提升到了512位,除了要求寄存器宽度同样加大一倍之外,它也需要运算单元的宽度加大一倍,在Skylake-SP上可以同时执行两个512位AVX向量运算,其中一个由原本256位宽度的Port 0和Port 1融合而成,另一个则是由Port 5端口扩展而成,这两个512位执行端口都可以支持512位FMA融乘加操作,但是,只有高端的Skylake-SP(Platinum 81xx和Gold 61xx)才具备Port 5的FMA融乘加单元。此外,桌面端(除了与Skylake-SP同源的Skylake-E之外)不支持AVX-512指令,这是因为这个功能需要额外的晶体管:

Skylake-SP Core:在标准Skylake Core微架构之外附加额外的512位端口5能力扩展与额外的768KiB L2 Cache扩展
Skylake-SP(以及Skylake-E)的AVX-512和第二个FMA,以及与普通Skylake相比多出的768KiB L2缓存,是在标准的Skylake Core之外的地方实现的,这部分区域已经属于Uncore核外区域,但被Skylake-SP拿来融入Core核内做核内用途。只有Skylake-SP有这些可能性进行这个操作,因为企业级处理器的Uncore区域向来都是采用与桌面端Uncore不同的特别设计。由于Skylake-SP的额外占用Uncore空间的设计,Skylake-SP的每核心L3 Cache容量比以往有所降低,测试表明这样的设计仍然是值得的,因为Skylake Core的内存子系统进行了相当多的优化:
2017-07-14勘误:E是以前由对应Xeon的某个型号改头换面的Core i7至尊版酷睿的代号后缀,Skylake的对应版本已经更改为X后缀——Skylake-X,对应地,Core命名的系列名变成了i9。

Skylake-SP Core:内存子系统
从参数上看,Skylake-SP的L1 D-Cache的吞吐量得到了倍增,以满足AVX-512向量指令的数据宽度倍增的情况,Skylake的Cache/TLB子系统也得到了全面的提升。关于AVX-512指令集,以及内存子系统方面的内容,我们放在了下一篇文章当中,接下来我们先看看我们先完成的SPEC CPU2006测试套件的其中一个配置的测试。
来源:至顶网CBSi企业方案解决中心频道
好文章,需要你的鼓励


亚马逊将从Rivian分拆公司Also采购数千辆助力货运车
Rivian分拆公司Also与亚马逊达成多年合作协议,将为这家电商巨头提供数千辆新型踏板助力四轮货运车TM-Q。该车辆载重超过400磅,体积小巧可使用自行车道。双方将合作定制车辆以满足亚马逊在欧美的配送需求,预计2026年春季投入使用。Also从Rivian内部项目发展而来,今年独立融资1.05亿美元,将利用可拆卸电池技术和专业物流软件为密集城区提供最后一公里配送解决方案。

如何让机器同时“看见“和“听见“?Character AI推出革命性音视频生成模型OVI
Character AI联合耶鲁大学开发的OVI系统实现了音视频的统一生成,通过"孪生塔"架构让音频和视频从生成之初就完美同步。该系统在5秒高清内容生成上显著超越现有方法,为多模态AI和内容创作领域带来突破性进展。

Accel与Prosus联手支持印度早期创业公司
知名投资机构Accel和Prosus宣布建立新的投资合作伙伴关系,专门支持印度初创企业从零开始发展,重点关注那些能够为南亚地区大众提供大规模解决方案的创始人。这是Prosus首次在企业成立阶段进行投资。双方将从创业公司最早期开始共同投资,专注于解决自动化、能源转型、互联网服务和制造业等领域的系统性挑战,初始投资金额从10万到100万美元不等。

南洋理工大学重磅突破:AI图像编辑的“调色板革命“让人人都能成为修图大师
这项由南洋理工大学研究团队开发的DragFlow技术,首次实现了在先进AI模型FLUX上的高质量区域级图像编辑。通过创新的区域监督、硬约束背景保护和适配器增强等技术,将传统点对点编辑升级为更自然的区域编辑模式,在多项基准测试中显著超越现有方法,为图像编辑技术带来革命性突破。
2017
07/11
12:02
分享
点赞

联想戴炜:混合式人工智能加速AI普惠,超级智能体引领智慧城市4.0
小红书入局AI智能体开源DeepAgent,在计划什么更新?
PTC:高科技企业数字化转型的4个案例
亚马逊将从Rivian分拆公司Also采购数千辆助力货运车
Accel与Prosus联手支持印度早期创业公司
CIO们在AI时代最看重新员工的哪些能力
LockBit 5.0扩大攻击范围,勒索软件威胁持续升级
AI时代的身体黑客:病理学新发现
COI Energy解决企业售电难题:让闲置电力变现
高通发布AI加速器并计划部署在神秘机架系统中
华盛顿大学Pedro Domingos:当神经网络遇上逻辑推理,Tensor Logic能否成为AI的通用语言?
IBM推出Digital Asset Haven平台助力银行政府安全管理加密货币

{kind=link}
{kind=link}
{kind=link}
{kind=link}