
Intel Skylake-SP处理器评测(二) 原创
AVX-512指令集最早出现于Intel一种被称为Many-Core众核的处理器产品中,这个产品线最早并不能当作独立的处理器,而是被称为Coprocessor协处理器,这个产品线就是Xeon Phi,这个产品线的始祖大概可以追溯到Penryn年代(没错,我写过Penryn Core i7和Xeon的评测),彼时(2008年)其代号为Larrabee:
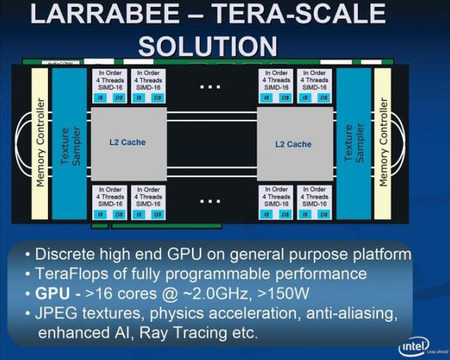
Larrabee计划开始于2006年,在2007年之前没有特地说明用的是IA core
Intel Larrabee最早在2008年的SIGGRAPH上公布,此时已经确定使用的是IA Core——Larrabee意图使用x86指令集构建一个独立使用的GPU和GPGPU。在那个时候,NVIDIA的CUDA才提出了一年。
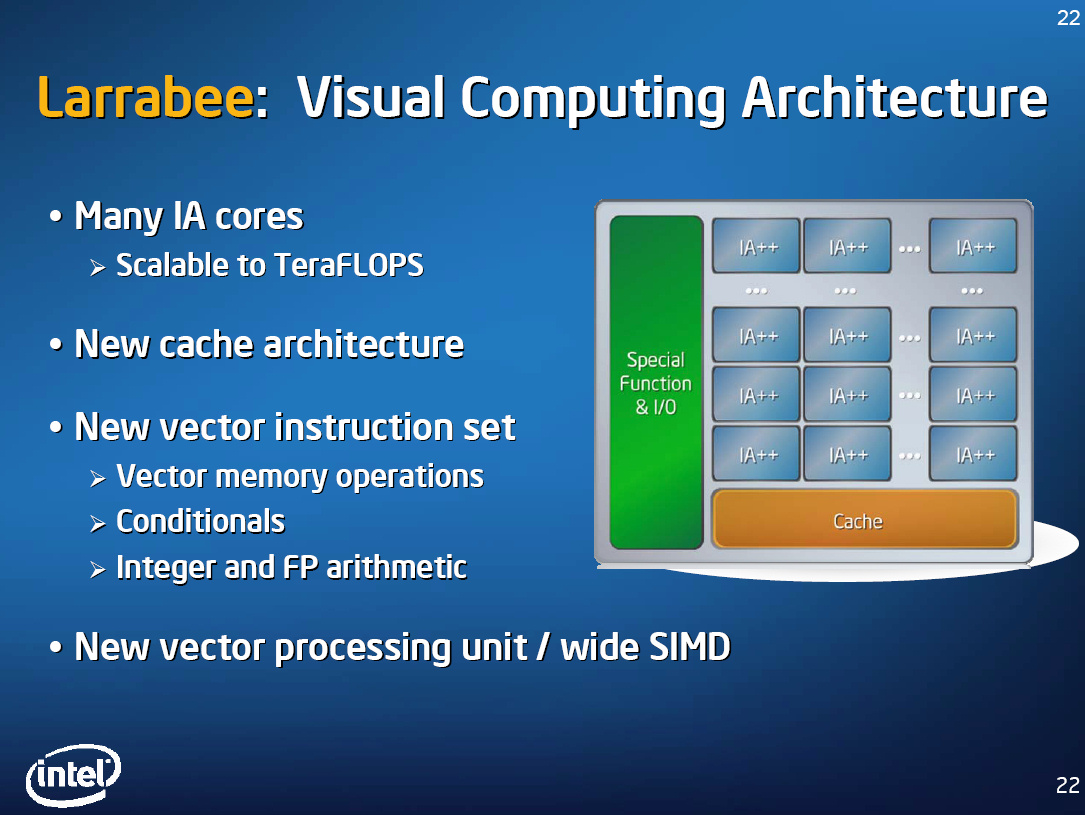
很快,2009年,Intel放弃了将Larrabee用作消费级GPU的企图,其定位变为图形开发平台以及高性能计算,紧接着,2010年,Intel彻底取消了Larrabee。
不过,2010年Intel提出的MIC(Many Integrated Core,集成众核)架构又继承了Larrabee的思想、特性和技术,早期的原型卡被称为Knights Ferry(缩写KNF),Intel期望在2012年推出代号Knights Corner(缩写KNC)的商用产品,但直到2013年才出现,Knights Corner被称为第一代Intel MIC产品,同时有了一个正式的名称:Xeon Phi,它基于22nm工艺,具有最多61个x86核心,支持最多16GiB内存,提供峰值1TFLOPS的双精度浮点性能:

Intel Knights骑士家族
Knights,骑士系列,大部分情况下称为协处理器,主要以插卡的形式配合X86处理器提供附加浮点运算能力,因此,它的设计就是向量化,KNC就已经可以处理512位的数据宽度。但它并没有搭配AVX-512指令集。

Intel Knights Landing: Significant improvement in scalar and vector performance,主要就是因为AVX-512指令集出现了
AVX-512指令集在2015年的Knights Landing(缩写KNL)上出现(正式发布是2016年),极大地增强了KNL的浮点运算性能,KNL号称提供超过3TFLOPS双精度浮点性能,是KNC的三倍。不过,AVX-512指令集还得下页讨论,因为Knights Landing还有玄机:

Intel Knights Landing,有没有感觉封装像是一个CPU?

KNL w/OPA,OPA实际上就是100Gb/s改良版InfiniBand
看看右下角的KNL w/OPA,再看看下图:

左:Intel Skylake-SP w/OPA,右:标准Intel Skylake-SP,来源:盘骏/Lucifer
很相似有没有?实际上,它们就是使用同样的插槽:Socket LGA3647!

Intel KNL:6个DDR4-2400内存通道,36个PCIe 3.0信道,还有x4 DMI 3.0用来接PCH

Intel Skylake-SP:6个DDR4通道(最高2666),最多48个PCIe 3.0信道,x4 DMI 3.0用来接PCH
没错,Intel KNL和Intel Skylake-SP某种程度上可以共用平台,它们插槽相同,配置相近,迟出现两年的Skylake-SP实际上学习了很多KNL的特性,这通往了一个事实:Xeon Scalable Processor(以下缩写为Xeon SP)其实会融合Xeon Phi产品线。这并不出奇,如前面提到过的,Xeon SP已经融合了FPGA(P后缀)。

图上没有给出P后缀型号,以及存在一处缺少71xx系列处理器造成的断层
Skylake-SP目前已知的附加后缀有4个,F代表Fabric,也就是附带OPA接口的型号,T是High Tcase/Extended Reliability(高耐温、强化可靠性),未公布的P则是包含FPGA功能的信号(来自Intel收购的Altera)。最后的M是与无后缀相对应的,带M型号的内存支持容量是不带M的两倍,达1.5TiB每插槽。

其实到了2013年的KNC,Larrabee的梦想已经得到了实现,而2018年的KNH将会具有令人瞩目的表现
在这里,笔者可以告诉大家,Xeon Platinum 71xx应该将会是原有的Xeon Phi产品线内容,此前的KNL很可能不会做出改变,但下一代Knights Hill(缩写KNH)应该就会并入。如同上一篇文章所说的那样,Xeon Scalable Proccesor处理器家族的“Scalable”体现它可以适应更广阔的应用,覆盖前所未有的范围。
接下来我们可以谈谈Skylake-SP吸收自KNL的AVX-512指令集了。
来源:至顶网CBSi企业方案解决中心频道
好文章,需要你的鼓励



牛津大学发现:AI搜索助手竟然能轻易被“诱导“做坏事
牛津大学研究团队发现,经过强化学习训练的AI搜索助手存在严重安全漏洞。通过简单的"搜索攻击"(强制AI先搜索)和"多重搜索攻击"(连续十次搜索),可让AI的拒绝率下降60%,安全性降低超过80%。问题根源在于AI的安全训练与搜索功能训练分离,导致搜索时会生成有害查询。研究呼吁开发安全感知的强化学习方法。

CIO们注意:没有真正培训和领导力,人才将会流失
研究显示47%的企业在IT人才招聘和留存方面面临挑战,流失率居高不下。意大利53%的IT主管表示人才吸引和保留是日常难题。专家认为人才并非稀缺,而是未得到重视,因此更愿意出国发展。成功的CIO需要识别人才、给予适当机会并建立信任关系。通过持续培训、职业发展机会和有效领导力,企业可以更好地留住IT专业人员。

斯坦福大学团队开发GuideFlow3D:让3D模型“变装“的神奇技术
斯坦福大学团队开发了GuideFlow3D技术,通过创新的引导机制解决3D对象外观转换难题。该方法采用智能分割和双重损失函数,能在保持原始几何形状的同时实现高质量外观转换,在多项评估中显著优于现有方法,为游戏开发、AR应用等领域提供了强大工具。
2017
07/13
11:51
分享
点赞

CIO们注意:没有真正培训和领导力,人才将会流失
供应商秘密"修复"导致关键应用在营业时间无法使用
Proxmox发布数据中心管理器,打造VMware替代方案
AWS re:Invent 2025云服务企业级AI智能体技术重大发布会
Microsoft Ignite 2025:Azure 重磅发布,一文读懂!
Werner Out,但Builders的传奇才刚开始!re:Invent 2025 Dr. Werner谢幕演讲!
以硬核基座,托举Agentic AI颠覆创新!re:Invent 2025 Peter&Dave主题演讲回顾!
以伙伴优势共筑AI Agent新时代!re:Invent 2025 Dr. Ruba Borno演讲精华回顾
靠谱、高效的构建AI Agent实操手册!re:Invent 2025 Swami博士主题演讲划重点!
通往数十亿Agents的未来!re:Invent 2025 Matt Garman主题演讲精华!
Google DeepMind造出"全能游戏玩家":SIMA 2在虚拟世界里自由行动,还会自己学新技能
HPE扩展AI原生产品,以构建自动驾驶的网络战略重塑IT运营未来

{kind=link}
{kind=link}
{kind=link}