
Intel Skylake-SP处理器评测(二) 原创
AVX-512是典型的SIMD(Single Instruction Multiple Data,单指令多数据)指令集,它可以认为是256位的AVX 2.0的扩展,SIMD宽度达到了512位。AVX(Advanced Vector Extensions,高级矢量扩展)当中的Vector矢量(也就是向量)一词就已经标明了其为一个SIMD指令集。矢量化,或者说向量化,是提升数据处理能力的一个重要手段。

AVX-512 - KNL and future Xeon:是的,一切早有预谋
我们先来看AVX-512要求的根本性架构改变:

SSE->AVX-2->AVX-512,16xXMM->16xYMM->32xZMM,笔者担心的是,未来的AVX-1024的寄存器该叫什么?
如果你了解过AVX 1.0(通常简略为AVX或AVX1)和AVX 2.0(AVX2或AVX-2),那么AVX-512也很好理解:数据处理宽度翻倍,在硬件上,它需要将处理器的AVX寄存器的宽度和数量都进行翻倍。新的AVX-512指令集将使用被称为ZMM0-31的32个512位寄存器,其中,16个就是原有的AVX 2.0使用的256位YMM寄存器加宽,然后新增加了16个新的512位寄存器。需要特别注明的是,新增加的寄存器必须运行在64位模式才能进行存取。
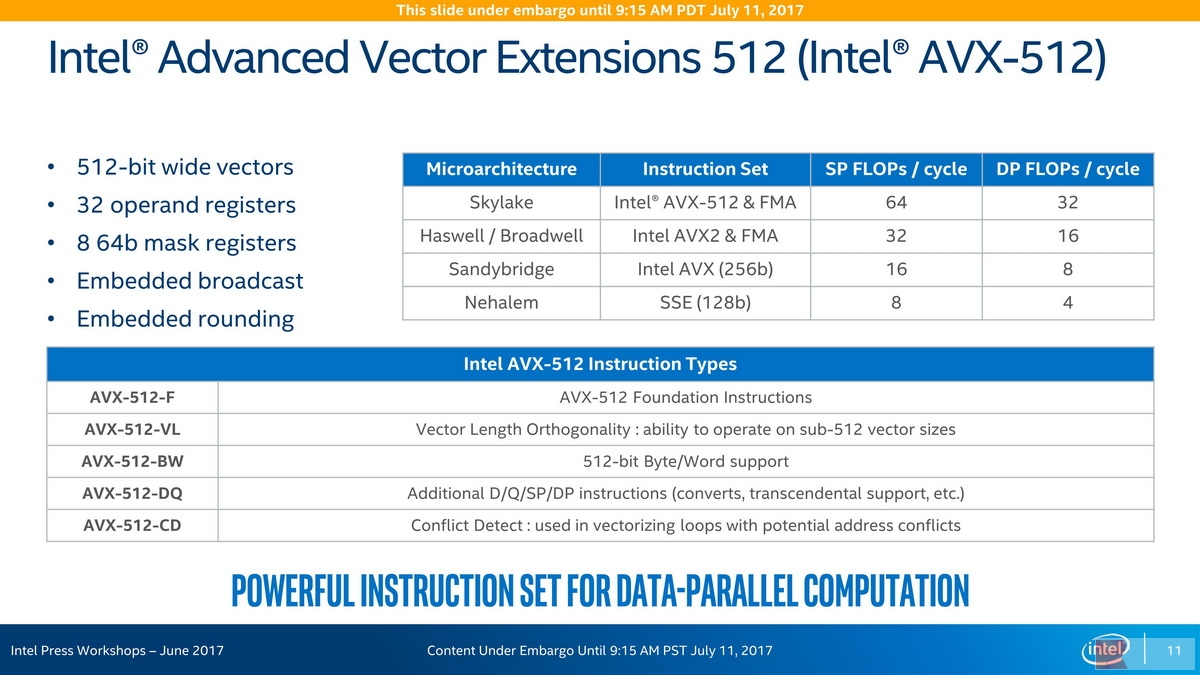
Intel AVX-512 on Intel Skylake-SP:AVX-512-(F, VL, BW, DQ, CD)
说到寄存器必须说到的是,在Skylake-SP的微架构设计当中,使用的是寄存器重命名,实际上是将操作数当中的寄存器重定位到寄存器当中的某些寄存器上,这种虚拟的对应可以消除大量的寄存器move操作——只需要建立新的指向即可。因此,AVX-512指令集要求的32个ZMM寄存器,实际上没有必要反映出来,当然,寄存器的宽度最好实装,如下图所示,实际增加了12个整数寄存器,浮点寄存器并没有变化,就这样支持了AVX-512指令集。
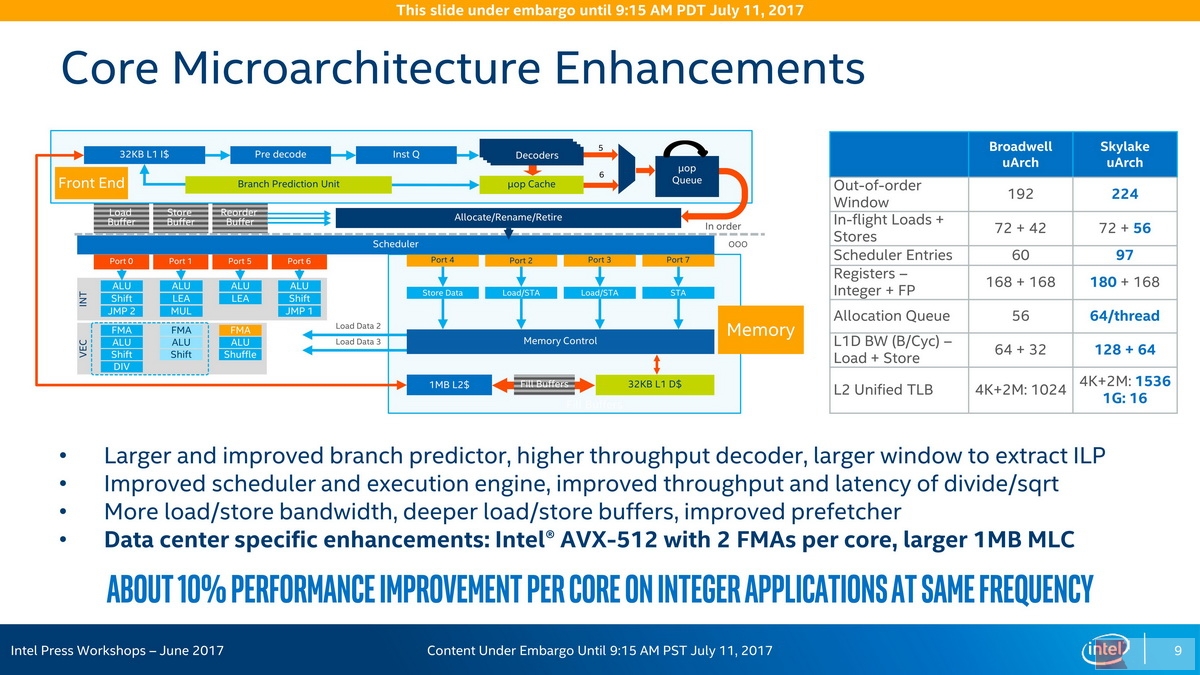
Intel Skylake-SP Core Microarchitecture:增加了12个整数寄存器
这12个整数寄存器可能包含了8个64位的mask寄存器,这些寄存器用来精细控制SIMD指令执行的对象,披露,只对512位总长数据中的某几个数据进行操作,而掠过某几个其他的数据。Skylake-SP的AVX-512还内置了广播和取整功能,在以往,使用什么规格的浮点取整方式是全局设定的,现在,每一条指令都可以设置自己的取整方式,这可以让指令的执行变得更为灵活。
AVX-512当中最让人迷惑的可能就是其包含的众多子集合了,Intel Skylake-SP搭载的是AVX-512-(F, VL, BW, CD):

F指Foundation,基础。AVX-512F就是基础的AVX-512指令集,为MIC与Xeon当中通用的部分(到了未来,就变成Xeon SP的基础部分了)。CD则是Conflict Detection,冲突检测,类似的机制在Core微架构的MOB(Memory Ordering Buffer)复合体中存在,实质上是以地址冲突检测搭配机遇性执行来充分发掘指令的执行度(上图中说的是向量化循环)。ER和PR则是Exponential指数操作和Prefetch预取操作,前者还包含了倒数操作(或者说,以-1为幂的指数),这两个指令集扩展不受SKL-SP支持而存在于KNL当中。

DQ这是Double and Quad word指令——双字/四字指令,包含了AVX-512F当中不具备的所有packed 32位/64位操作。BW这是Byte and Word指令,字节/字指令,将packed指令扩展到字节和字(8位和16位),如此一次性可以处理64个/32个数据。这个指令集也给出了MMX/SSE2/AVX2指令对应的AVX-512原语。VL这是Vector Length扩展——向量长度扩展,它的含义是,AVX-512指令集也可以对128位或者256位数据进行处理。
接下来可能是比较少为人知的几个新指令集:

请允许我们暂时忽略其他,只介绍最后一个:XSAVE{S,C},它用来保存扩展的处理器状态,包括AVX-512指令集在内,需要新的XSAVE指令集支持,以在线程切换的时候,保存/恢复这些新寄存器的数据。
关于AVX-512暂时介绍到这里,接下来我们将会展开对其进行的测试。
来源:至顶网CBSi企业方案解决中心频道
好文章,需要你的鼓励



牛津大学发现:AI搜索助手竟然能轻易被“诱导“做坏事
牛津大学研究团队发现,经过强化学习训练的AI搜索助手存在严重安全漏洞。通过简单的"搜索攻击"(强制AI先搜索)和"多重搜索攻击"(连续十次搜索),可让AI的拒绝率下降60%,安全性降低超过80%。问题根源在于AI的安全训练与搜索功能训练分离,导致搜索时会生成有害查询。研究呼吁开发安全感知的强化学习方法。

CIO们注意:没有真正培训和领导力,人才将会流失
研究显示47%的企业在IT人才招聘和留存方面面临挑战,流失率居高不下。意大利53%的IT主管表示人才吸引和保留是日常难题。专家认为人才并非稀缺,而是未得到重视,因此更愿意出国发展。成功的CIO需要识别人才、给予适当机会并建立信任关系。通过持续培训、职业发展机会和有效领导力,企业可以更好地留住IT专业人员。

斯坦福大学团队开发GuideFlow3D:让3D模型“变装“的神奇技术
斯坦福大学团队开发了GuideFlow3D技术,通过创新的引导机制解决3D对象外观转换难题。该方法采用智能分割和双重损失函数,能在保持原始几何形状的同时实现高质量外观转换,在多项评估中显著优于现有方法,为游戏开发、AR应用等领域提供了强大工具。
2017
07/13
11:51
分享
点赞

CIO们注意:没有真正培训和领导力,人才将会流失
供应商秘密"修复"导致关键应用在营业时间无法使用
Proxmox发布数据中心管理器,打造VMware替代方案
AWS re:Invent 2025云服务企业级AI智能体技术重大发布会
Microsoft Ignite 2025:Azure 重磅发布,一文读懂!
Werner Out,但Builders的传奇才刚开始!re:Invent 2025 Dr. Werner谢幕演讲!
以硬核基座,托举Agentic AI颠覆创新!re:Invent 2025 Peter&Dave主题演讲回顾!
以伙伴优势共筑AI Agent新时代!re:Invent 2025 Dr. Ruba Borno演讲精华回顾
靠谱、高效的构建AI Agent实操手册!re:Invent 2025 Swami博士主题演讲划重点!
通往数十亿Agents的未来!re:Invent 2025 Matt Garman主题演讲精华!
Google DeepMind造出"全能游戏玩家":SIMA 2在虚拟世界里自由行动,还会自己学新技能
HPE扩展AI原生产品,以构建自动驾驶的网络战略重塑IT运营未来
