
新华三H3C R4700 G3高密机架服务器评测 原创
除了整数运算和浮点运算的差别之外,SPEC CPU2006测试还分两种:SPEED测试和RATE测试,SPEED测试类型运行单个实例,用来测试系统运行单作业的时候的运算能力,RATE测试则是运行多个实例,用来测试系统的总运算吞吐能力。SPEC CPU测试还会给出两种类型的结果:Base基准测试结果和Peak峰值测试结果,Base测试要求编译器套件按照指定的规则进行优化,而Peak测试则可以允许使用更多的优化技术,可以看出,前者可以用来简单对比不同的平台,而后者则在对比因素中加入了编译器等因素,有实力编写编译器的厂商可以从中获益。本页给出的是SPEED测试结果,按照整数到浮点、Base测试到Peak测试排列四个成绩图标,每个图表给出了测试系统及对比系统的每个子项目的成绩。图表图例文字中最后的"2S32C64T"字段指的是2 Sockets、32 Cores、64 Threads,意思是“2插槽32核心64线程”。
时间紧迫,我们没有进行non-AVX的测试以和前数代官方平台进行对比,而是直接进行了已经普及的AVX2测试。对比的平台都是当时的顶级配置,尽管系统和编辑器与现在相比可能有所不如。我们先进行的是SPEED测试,这个测试中系统全力以赴运行一个实例——通常是一个进程,但编译器和操作系统可能会根据情况将其编译为多个线程并分散到多个核心上运行,因此有些项目会看到非常可观的性能表现:
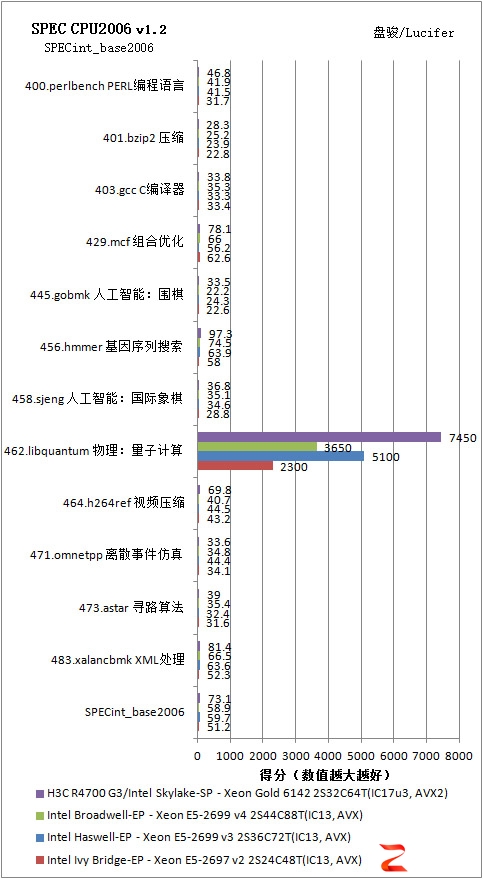
SPECint_base2006,整数,SPEED测试,Base基准测试

SPECint2006,整数,SPEED测试,Peak峰值测试
462.libquantum是一个模拟量子计算的子项目,它极大地依赖于内存性能,因此新的系统比上一代增加了50%的内存通道数量提供了无与伦比的优势。大部分SPEED测试均使用不超过2个CPU核心,因此通常Intel的处理器可以Turbo到最高频率(但运行AVX2代码又会降低一些频率)。在2个核心的情况下,2.6GHz的Skylake-SP/Xeon Gold 6142可以Turbo至3.7GHz(记住运行AVX2代码时又会降低一些频率),而Broadwell-EP/Xeon E5-2699 v4和Haswell-EP/Xeon E5-2699 v3的这个频率都是3.6GHz,Ivy Bridge-EP/Xeon E5-2697 v2则是3.5GHz。
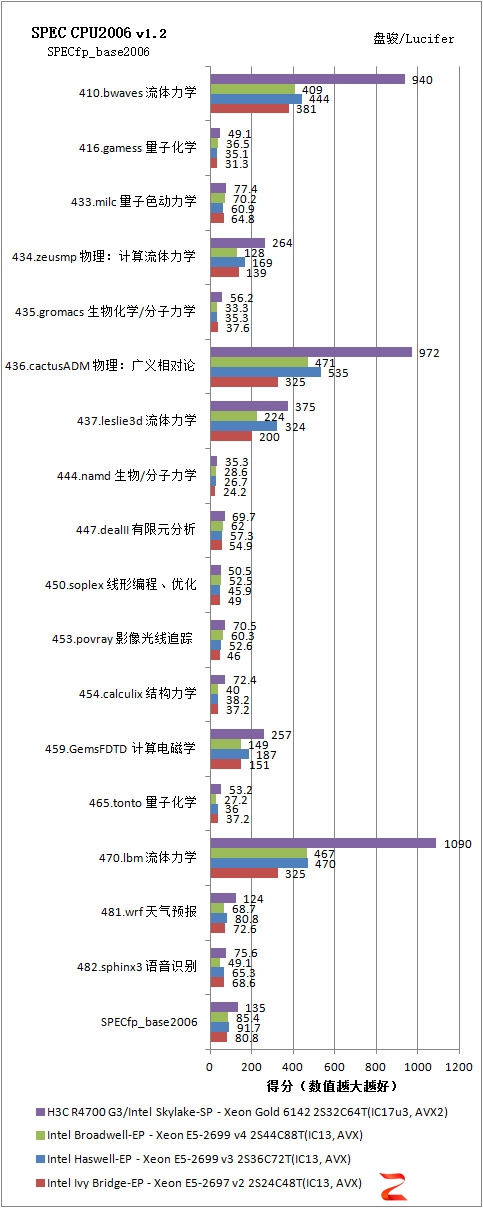
SPECfp_base2006,浮点,SPEED测试,Base基准测试
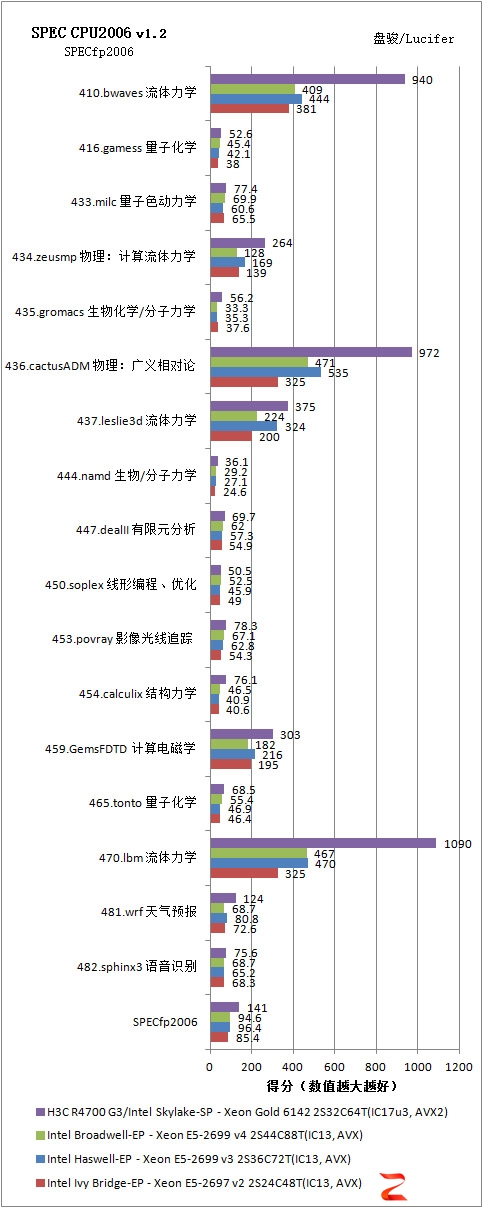
SPECfp2006,浮点,SPEED测试,Peak峰值测试
我们可以看到,基于Intel Xeon SP Gold 6142的H3C UniServer R4700 G3在单任务上提供了比上一代超出非常多的优势,SPECint_base2006为73.1,SPECfp_base2006为135。即使是考虑老平台也使用AVX2代码,我们以前的测试表明并没有多大的提升。
好文章,需要你的鼓励


Spotify年度盘点2025首次推出多人互动功能“盘点派对“
Spotify年度总结功能回归,在去年AI播客功能遭遇批评后,今年重新专注于用户数据深度分析。新版本引入近十项新功能,包括首个实时多人互动体验"Wrapped Party",最多可邀请9位好友比较听歌数据。此外还新增热门歌曲播放次数显示、互动歌曲测验、听歌年龄分析和听歌俱乐部等功能,让年度总结更具互动性和个性化体验。

NVIDIA联手多所高校推出SpaceTools:AI机器人有了“火眼金睛“和“妙手回春“
NVIDIA联合多所高校开发的SpaceTools系统通过双重交互强化学习方法,让AI学会协调使用多种视觉工具进行复杂空间推理。该系统在空间理解基准测试中达到最先进性能,并在真实机器人操作中实现86%成功率,代表了AI从单一功能向工具协调专家的重要转变,为未来更智能实用的AI助手奠定基础。

英国SAP用户因商业套件重启授权迷局感到困惑
英国SAP用户表示,Business Suite的授权和定价复杂性正在影响这一云应用新模式的推广。英国和爱尔兰SAP用户组织调查显示,仅27%的用户熟悉今年2月推出的重新设计版Business Suite。61%的受访者认为授权和定价模式是最需要了解的问题。用户在制定从传统系统迁移的商业案例时面临困难,特别是从ECC平台迁移到S/4HANA需要完整的业务转型。ECC主流支持将于2027年结束。

机器人学会“三思而后行“:中科院团队让AI机器人告别行动失误
这项研究解决了现代智能机器人面临的"行动不稳定"问题,开发出名为TACO的决策优化系统。该系统让机器人在执行任务前生成多个候选方案,然后通过伪计数估计器选择最可靠的行动,就像为机器人配备智能顾问。实验显示,真实环境中机器人成功率平均提升16%,且系统可即插即用无需重新训练,为机器人智能化发展提供了新思路。
2017
12/26
06:14
分享
点赞

Spotify年度盘点2025首次推出多人互动功能"盘点派对"
英国SAP用户因商业套件重启授权迷局感到困惑
AWS发布Graviton5定制CPU,为云工作负载带来强劲性能
美光放弃Crucial品牌:告别消费级存储市场
手机里的NPU越来越强,为什么AI体验还在原地踏步?
如何使用现有基础设施让数据做好AI准备
IT领导者快问快答:思科光网络公司首席数字信息官Craig Williams分享AI转型经验
Anthropic CEO警告AI行业泡沫化,批评"YOLO"式投资
雅虎利用AI实时总结橄榄球比赛精彩内容
押注AI智能体,奇奇科技跨越十年的“换挡”与远航
联想天禧AI及创新终端设备在2025 AIE博览会获两项大奖,引领个人AI体验创新
豆包手机助手调整部分AI能力 呼吁保障用户AI使用权

{kind=link}
{kind=link}
{kind=link}
{kind=link}