
Intel Broadwell-EP处理器评测
从Nehalem开始,Intel的处理器就可以分为Core和Uncore两大部分,其中,同一微架构的处理器,其Core部分是一致的,根据消费端、企业端的需求不同,使用不同的Core数量以及Uncore部分搭配组合,就得到了整个家族不同的处理器。Core,核心或者核内,属于Microarchitecture微架构的范畴,Uncore属于Architecture架构的范畴。概括起来,Broadwell的Core改进可以分为三个方面:
1.浮点运算性能提升
2.分支预测、TLB(Translation Lookaside Buffer,旁路翻译缓冲或翻译后备缓冲)以及微指令调度上性能提升
3.TSX-HLE/RTM+指令集的提升
如下图所示,可以看出:

不能否认的是,虽然上图将一大段改进冠以TLB改进的名义,但其实际上包含的内容超出了TLB的范围,我们认为,Broadwell理论上确实应该是工艺制程的提升节点,微架构改进本来不是其任务,但它却做了不少的改进,这应该是很多处地方Intel使用了“Broadwell微架构”字样的缘由。
首先我们来看Haswell的微架构图示,上图第二段落的改进应用在下图的前半部分,也就是Core/内核的前端部分:

Haswell Core at a Glance,Haswell核心一目了然
At a Glance,一目了然的意思,分支预测在前端的最前端,而TLB的位置在L1 Cache附近,微指令调度则是在后端(靠近前端的部分)。本质上,TLB也是一种Cache,它用于缓冲虚拟地址到物理地址的转换,以加快所有与这些地址相关的操作。前面几代Core Cache和TLB的规格如下:

三种微架构的缓冲大小、延迟以及带宽的改进:Nehalem、Sandy Bridge、Haswell
在Broadwell上,新增加了原生的16条1GiB的TLB项目(Haswell没有1GiB的L1I TLB,有4条1GiB的L1D TLB),这些1GiB L1D TLB将会提升大内存环境下的性能,并且STLB(Second Level TLB,也就是上面的L2 Unified TLB)从1K条增加到了1.5K条,提升了50%,这些改进都符合了时下系统内存越来越大的趋势。和TLB、Cache紧密集成的用于分支预测和返回的地址猜测功能也得到了提升,分支预测单元的目标阵列的组关联也从8路提高到了10路。后端的Out-of-Order Scheduler乱序执行调度器的大小也从60提高到了64:

里面的Scheduler Entries描述了乱序执行调度器的容量,Haswell从前一代的54提高到60,而Broadwell进一步提升到了64,同时,Broadwell也能发掘更多的微指令执行并行度
总的来说,和Haswell一样,Broadwell致力于进一步发掘处理器的ILP(Instruction Level Parallelism,指令集并行度)能力,按照图表,Broadwell的IPC(Instruction Per Cycle,每周期指令数)提升幅度达到了22%,当然,这个提升也有后端部分——执行单元的改进功劳,在Broadwell上,得到改进的主要是浮点运算性能,这个主要包含了稍后介绍的Divider除法器的改进,另外还有FMA——主要是MulPS/PD的性能提升,我们先看看Haswell的执行单元概况,Broadwell与之极为相似:

Broadwell的浮点乘法的延迟从5个周期降低到了3个周期:
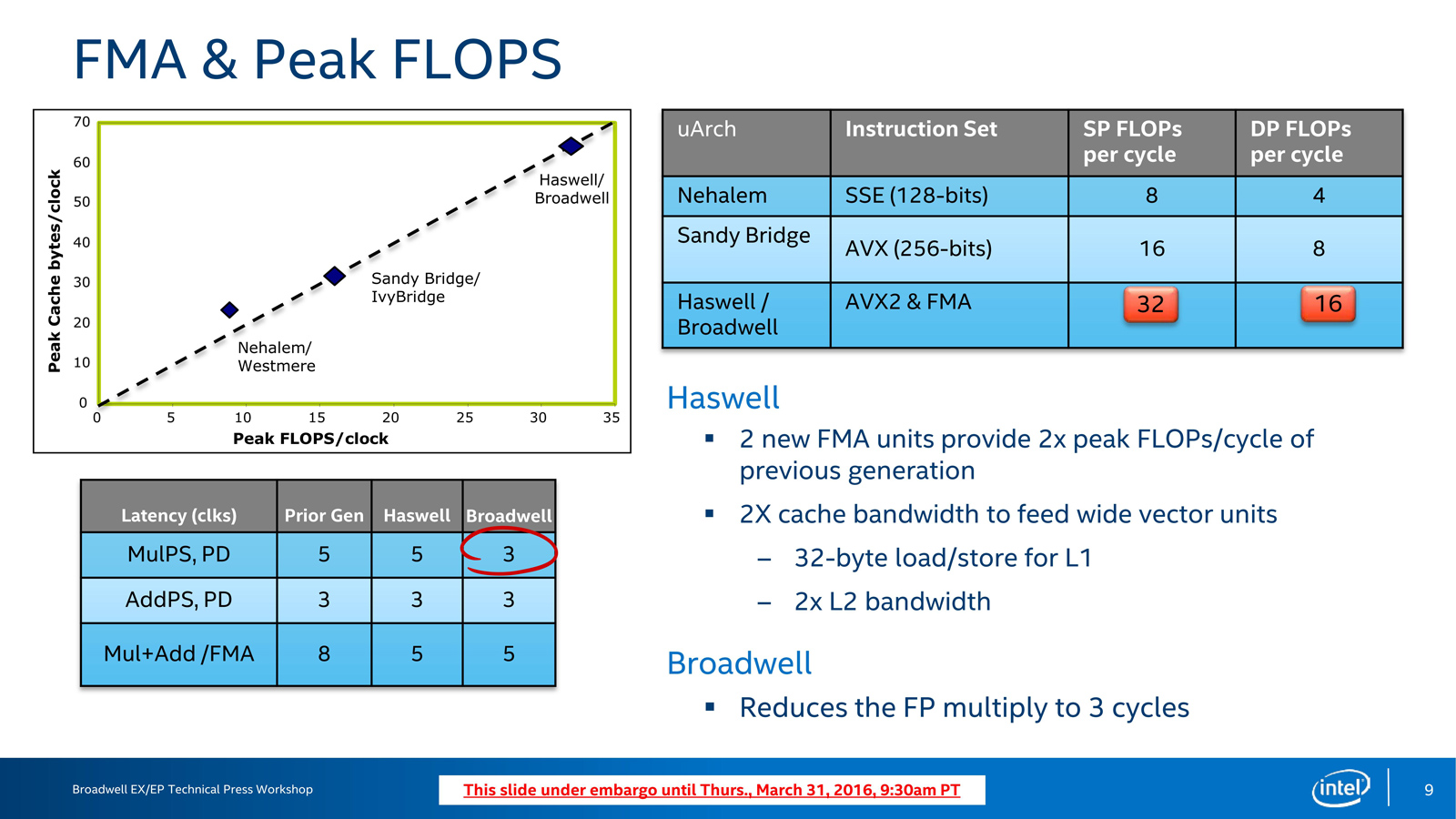
红圈就是Broadwell的改进:MulPS/PD(Multiply Packed SP/DP)的延迟从5个周期降低到了3个周期
接下来看Divider除法器:
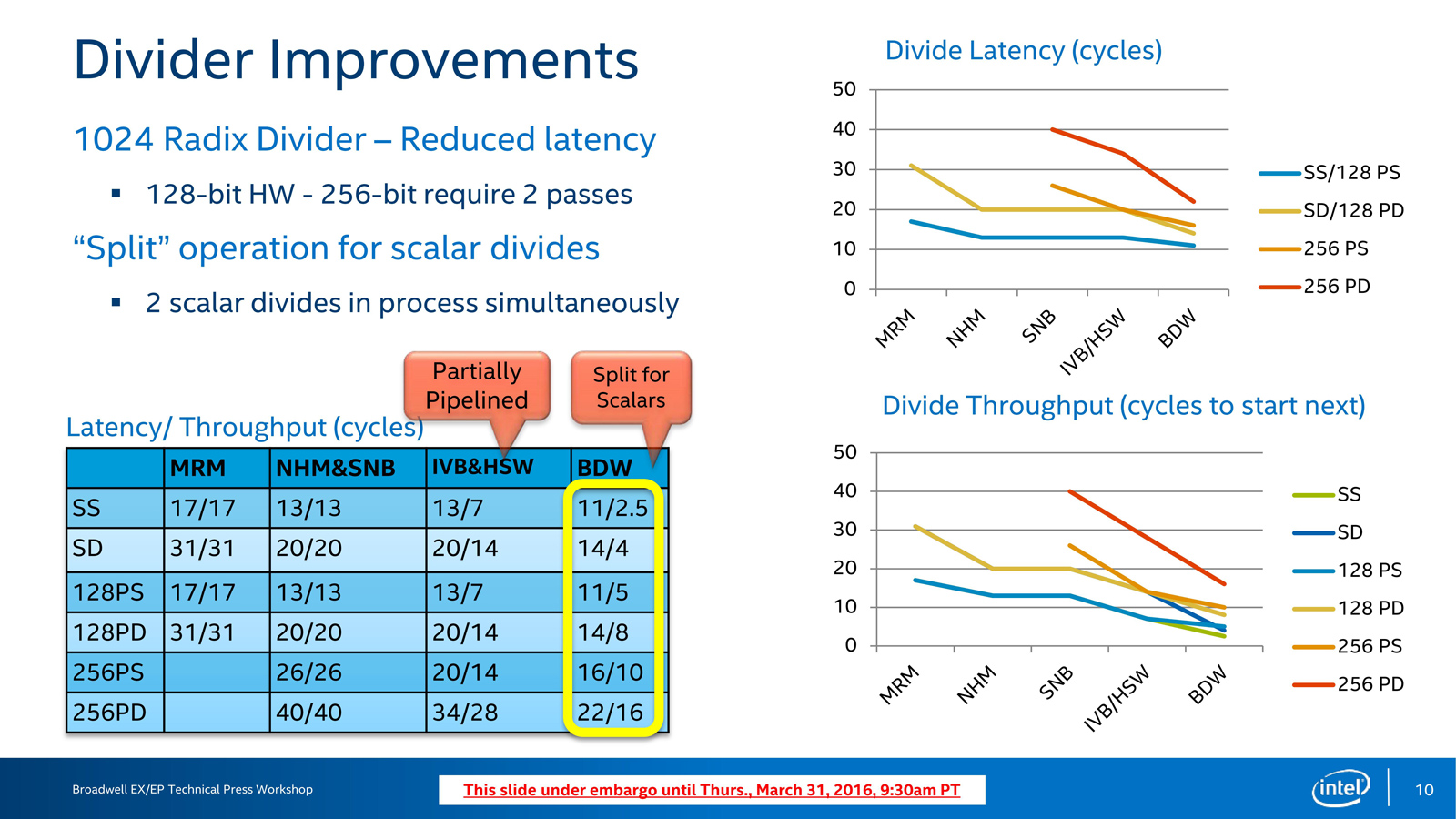
Divider除法器的提升是十分显著的,从最前面的图可以看到,除法器位于执行单元端口0
除法器是笔者十分关心的内容,为什么?因为在CPU设计当中,整数运算和逻辑运算已经做到了全流水化(Full Pipelined),但浮点运算特别是除法运算时至今日仍不能做到。除法器是浮点运算当中的核心部分。注意到上图红色标注的部分:“Partially Pipelined”,“部分流水化”,在Workshop上,笔者特别问及,这是否意味着IVB/HSW没有做到全流水化而BDW(也就是Broadwell)做到了?答案是否定的,Broadwell也没有全流水化。不过,Broadwell的128bit 1024 Radix Divider仍然得到了强大的提升(1024 Radix指明了除法器的构造),一个是降低了延迟,一个是可以划分为两个除法器,从而可以同时执行两个标量除法操作——这大为提高了执行的灵活性,也明显提升了性能,如上图左下所示,最复杂的256PD运算的延迟从34周期降低到22周期,吞吐延迟从28周期降低到了16周期(吞吐延迟指的是重复执行操作中可以执行下一条指令所需要等待的时间)。

这应该是Uncore部分的改进,被放到了Core部分
额外地,和浮点性能有关联的是AVX指令执行的提升(它其实应该放在Uncore部分),在以往,执行AVX指令的Core的将会具有一个较低的Turbo频率,而执行普通non-AVX指令的Core将运行在更高的频率,这是因为AVX指令集具有256bit的宽度,同时处理的数据量至少是non-AVX的两倍或以上。基于功耗、发热量的考虑,AVX核心频率会低一些——不仅仅如此,在Haswell及之前,执行AVX指令实际上会让所有的核心都运行在相对较低的AVX Turbo频率上。在Broadwell上,这种强制捆绑得到了解耦,现在AVX核心和non-AVX核心分别运行在各自的优化频率上。在Workshop上,笔者提问在AVX指令检测的恢复期是多少,答案是one microsecond,这个数字是不是有点太快了?
好文章,需要你的鼓励


Perplexity推出电视应用 率先登陆三星智能电视
三星与AI搜索引擎Perplexity合作,将其应用引入智能电视。2025年三星电视用户可立即使用,2024和2023年款设备将通过系统更新获得支持。用户可通过打字或语音提问,Perplexity还为用户提供12个月免费Pro订阅。尽管面临版权争议,这一合作仍引发关注。

浙江大学突破:让AI专家团队在考试时“动态组队“,推理能力飙升
浙江大学团队提出动态专家搜索方法,让AI能根据不同问题灵活调整内部专家配置。该方法在数学、编程等任务上显著提升推理准确率,且不增加计算成本。研究发现不同类型问题偏爱不同专家配置,为AI推理优化开辟新路径。

M5 MacBook Pro评测:优秀但缺乏新意
苹果M5 MacBook Pro评测显示这是一次相对较小的升级。最大变化是M5芯片,CPU性能比M4提升约9%,多核性能比M4 MacBook Air快19%,GPU性能提升37%。功耗可能有所增加但电池续航保持24小时。评测者认为该产品不适合M4用户升级,但对使用older型号用户仍是强有力选择。

清华大学新突破:AI模型居然能学会“少说话多做事“,推理效率提升一倍还更准确
清华大学研究团队提出SIRI方法,通过"压缩-扩张"交替训练策略,成功解决了大型推理模型"话多且准确率低"的问题。实验显示,该方法在数学竞赛题上将模型准确率提升43.2%的同时,输出长度减少46.9%,真正实现了效率与性能的双重优化,为AI模型训练提供了新思路。
2016
05/11
06:11
分享
点赞

IEEE:为何防钓鱼培训难有成效
Perplexity推出电视应用 率先登陆三星智能电视
M5 MacBook Pro评测:优秀但缺乏新意
智能CEO为何追踪"陌生指标"而非传统KPI
29家顶尖机构,联合定义通用人工智能AGI
西门子将八赴进博,以工业AI加速中国企业效率与绿色“双跃迁”
Dell Pro Max搭载GB10重塑AI开发体验
AI赋能 创意新生 —— 2025厦门国际动漫节“金海豚奖”48小时游戏开发大赛圆满收官
戴尔科技推出全新Dell Pro Essential笔记本电脑,专为中小型企业而打造
OpenAI推出浏览器ChatGPT Atlas并秘密培训金融专家
Chrome和Safari浏览器市场统治地位面临挑战 2025年最佳替代浏览器盘点
Google AI Studio推出"氛围编程"助力低门槛应用开发

{kind=link}
{kind=link}