
Intel Broadwell-EP处理器评测
【ZD Research】在以往,Tick-Tock钟摆策略让Intel(英特尔)的处理器每两年更换一次工艺制程(Tick)、每两年更新一次微架构(Tock),最终就是每年换一次制程或微架构,从而每年都能有新产品推出。现在,这个摆动的变慢我们已经用肉眼就可以看到,大致上,在微架构更换之后,还可能会接着推出一个同制程同微架构的改进版本,这样微架构周期就变成了约三年,例子就是桌面端的Broadwell-Skylake-Kaby Lake以及下一个循环中的Cannonlake-Ice Lake-Tiger Lake。
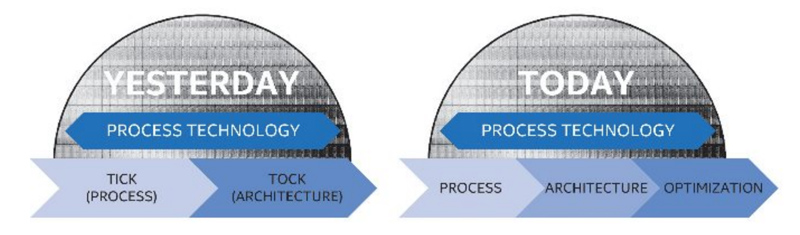
从Tick-Tock变为Process-Architecture-Optimization,笔者将其称为“Tick-Tock-Tock”(非官方)
新的策略称为“Process-Architecture-Optimization”——“制程-架构-优化”,导致这个变长的周期的原因就是临近10nm之后,新工艺制程的开发难度加大。上一代的企业级处理器产品线——代号Haswell-EP的企业级第三代至强E5处理器(Xeon E5 v3)在2014年9月发布,到现在代号Broadwell-EP的企业级第四代至强E5处理器(Xeon E5 v4),中间的跨度超过了一年半。相比消费级,企业级处理器具有很多额外的特性,从而需要额外的开发时间,导致了其周期变长,这种与消费级处理器的不匹配以后还可能会导致一些问题。

2016年4月,Intel Xeon E5-2600 v4处理器,代号Broadwell-EP(14nm,Broadwell微架构)
上图是我们拿到的Broadwell-EP——Xeon E5-2600 v4的实物。大约在发布前一个月,我们拿到了样品。在收到处理器(以及搭配的DDR4内存)的同时,笔者身处Oregon的Hillsboro,同时见到了Xeon E5 v4处理器、Xeon E7 v4处理器以及Xeon E5 v4的晶圆,其时Intel对晶圆的官方图片三缄其口,事实证明之后的发布会Intel再也没有提供详细的晶圆照片。幸运的是,在某Workshop上,笔者拍摄了一些晶圆照片,它们经过了Intel人员的审核,在后面我们会看到。

一颗Intel Xeon E5 v4和两颗Intel Xeon E7 v4(正面)

一颗Intel Xeon E5 v4和两颗Intel Xeon E7 v4(背面)
Process-Architecture-Optimization策略中包含了Broadwell,按照设计,Broadwell-EP和所有的Broadwell一样,都基于新的14nm工艺。这个新工艺带来了更多的晶体管,从而达到了更多的核心数量。除此之外,一如既往地,Broadwell-EP在Uncore区域做了很多的改变,有一些非常激动人心,就如我们接下来会看到的一样。

Intel Broadwell-EP处理器评测 by ZD Research 盘骏/Lucifer
首先,我们会先对Broadwell-EP的架构进行一个概述,然后是对Broadwell-EP的微架构改进进行解析,然后着重对Broadwell-EP的Uncore区域——内联架构——当中的上面提到的激动人心的改进进行介绍,然后是一些杂项Uncore改进,最后是平台方面的变化,然后就是性能测试并与前几代理器进行性能对比。
前两代处理器Ivy Bridge-EP和Haswell-EP的评测:


好文章,需要你的鼓励


微软推出Memora,致力于解决AI智能体的记忆难题
微软研究院发布Memora记忆系统,旨在解决AI智能体在长期部署中记忆碎片化、检索效率低的问题。Memora通过将存储内容与检索方式解耦,引入"主抽象"与"线索锚点"双组件架构,在LoCoMo和LongMemEval两项基准测试中表现优异,上下文token用量最高可降低98%。但专家提醒,实际企业成本还需考虑索引、存储及合规审计,且该项目目前仍处于研究阶段,尚未达到生产就绪水平。

马里兰大学研究团队揭秘:机器人AI的“语言大脑“到底有多臃肿?
这项马里兰大学与思科研究院的联合研究发现,VLA机器人模型的语言模块存在严重冗余——砍掉一半语言层后成功率不降反升,而视觉和动作模块则高度敏感。

SGE计划在英国部署14座BWRX-300小型模块堆,总装机容量达4.2吉瓦
波兰小型模块化反应堆开发商SGE宣布计划在英国三个地点部署14台GE Vernova Hitachi的BWRX-300机组,总装机容量达4.2GW,可满足英国约11%的电力需求。该项目已依据英国《先进核能框架》提交申请,采用差价合约融资模式,预计2026年11月进入先进核能管道,首台机组目标于2034年投入商业运营。

验证太急,反而会帮倒忙——以色列独立研究员揭示多智能体AI系统中“过度纠错“的危险陷阱
研究揭示多智能体AI系统中验证存在"最优剂量":纠错太强或延迟太长会让AI团队陷入震荡,黄金比例倒数0.618是延迟两轮时的精确稳定阈值。
2016
05/11
06:09
分享
点赞

SGE计划在英国部署14座BWRX-300小型模块堆,总装机容量达4.2吉瓦
特斯拉在迈阿密划定Robotaxi小范围服务区,得克萨斯扩张仍受阻
Luxonis完成1400万美元融资,为智能自动化打造视觉感知层
.NET 8 与 .NET 9 即将停止支持,微软建议升级至 .NET 10
苹果供应商塔塔电子遭黑客攻击,iPhone 18 Pro核心机密外泄
美国解除对Anthropic旗下Fable 5和Mythos 5大语言模型的出口限制
Meta推出定制CXL芯片Vistara,让旧内存在新服务器中焕发新生
Bending Spoons完成180亿美元IPO,创始人谈如何将运气从成功方程式中剔除
浏览器大战进入新阶段:Chrome与Safari之外的最佳替代选择
华盛顿特区都会区迎来首批途中电动公交充电桩
Meta即将发布具备更强编程能力的全新AI模型
2025年AI核心术语完全指南

{kind=link}
{kind=link}