
Intel Broadwell-EP处理器评测
同时得到较大提升的还有安全特性,主要包括一些指令的延迟降低,并加入了新的指令,以及支持RDSEED——对随机数产生器运行方式上的改进,最后是SMAP——虚拟化方面的改进。经过长久的发展,虚拟化特性的重点当前已经转移到Uncore部分,包括APIC中断管理器以及PCIe Root Complex上,但仍有一些指令集方面的改进是包含在Core核心内,以下是这些特性的简单介绍:

Broadwell:四类安全特性改进

加密方面的性能提升是比较显著的,PCLMULQDQ操作的乘法器的吞吐量翻倍,延迟降低;由于新指令ADCX/ADOX的加入,RSA类操作的提升可以达到60%以上

RDSEED:Non-Deterministric Random Bit Generator,不确定性随机位产生器
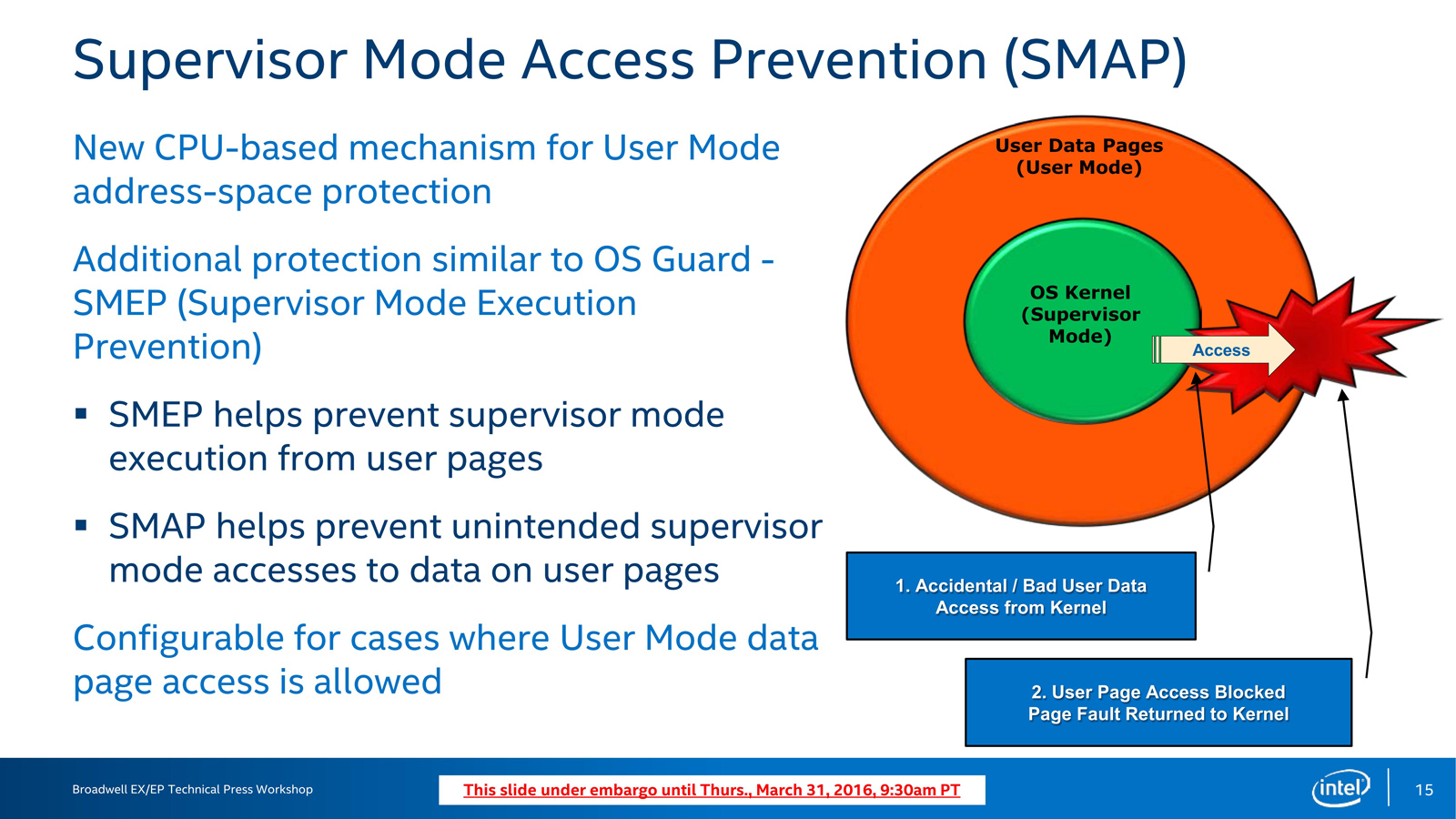
SMAP类似于SMEP,避免超级管理器模式下无意访问用户页面的数据(SMEP则是反过来)

Intel TSX:Transactional Synchronization Extensions,事务同步扩展,现在终于在Xeon E5上可用了
需要特别一提的是最后的Intel TSX指令集,Broadwell中,各种粒度模式下的性能都得到了改进。限于时间关系,不详细介绍,以下是Haswell上的介绍:

Intel Haswell专门针对锁和同步性能进行了加强

TSX:Transactional Synchronization Extensions,事务同步扩展

Intel TSX可以实现锁消去
再一次地,和核心架构的改进不同,指令集的增强需要程序使用新的指令集进行编写和编译。不过,TSX笔者预计将来是一个可以提供显著影响的特性。
好文章,需要你的鼓励



牛津大学发现:AI搜索助手竟然能轻易被“诱导“做坏事
牛津大学研究团队发现,经过强化学习训练的AI搜索助手存在严重安全漏洞。通过简单的"搜索攻击"(强制AI先搜索)和"多重搜索攻击"(连续十次搜索),可让AI的拒绝率下降60%,安全性降低超过80%。问题根源在于AI的安全训练与搜索功能训练分离,导致搜索时会生成有害查询。研究呼吁开发安全感知的强化学习方法。

CIO们注意:没有真正培训和领导力,人才将会流失
研究显示47%的企业在IT人才招聘和留存方面面临挑战,流失率居高不下。意大利53%的IT主管表示人才吸引和保留是日常难题。专家认为人才并非稀缺,而是未得到重视,因此更愿意出国发展。成功的CIO需要识别人才、给予适当机会并建立信任关系。通过持续培训、职业发展机会和有效领导力,企业可以更好地留住IT专业人员。

斯坦福大学团队开发GuideFlow3D:让3D模型“变装“的神奇技术
斯坦福大学团队开发了GuideFlow3D技术,通过创新的引导机制解决3D对象外观转换难题。该方法采用智能分割和双重损失函数,能在保持原始几何形状的同时实现高质量外观转换,在多项评估中显著优于现有方法,为游戏开发、AR应用等领域提供了强大工具。
2016
05/11
06:11
分享
点赞

CIO们注意:没有真正培训和领导力,人才将会流失
供应商秘密"修复"导致关键应用在营业时间无法使用
Proxmox发布数据中心管理器,打造VMware替代方案
AWS re:Invent 2025云服务企业级AI智能体技术重大发布会
Microsoft Ignite 2025:Azure 重磅发布,一文读懂!
Werner Out,但Builders的传奇才刚开始!re:Invent 2025 Dr. Werner谢幕演讲!
以硬核基座,托举Agentic AI颠覆创新!re:Invent 2025 Peter&Dave主题演讲回顾!
以伙伴优势共筑AI Agent新时代!re:Invent 2025 Dr. Ruba Borno演讲精华回顾
靠谱、高效的构建AI Agent实操手册!re:Invent 2025 Swami博士主题演讲划重点!
通往数十亿Agents的未来!re:Invent 2025 Matt Garman主题演讲精华!
Google DeepMind造出"全能游戏玩家":SIMA 2在虚拟世界里自由行动,还会自己学新技能
HPE扩展AI原生产品,以构建自动驾驶的网络战略重塑IT运营未来
